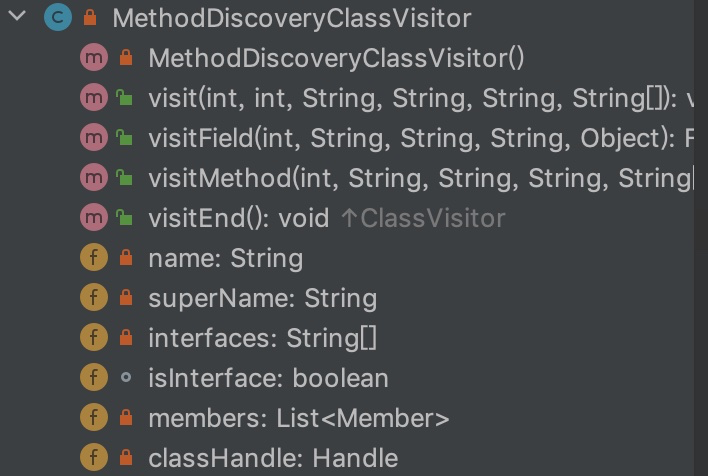
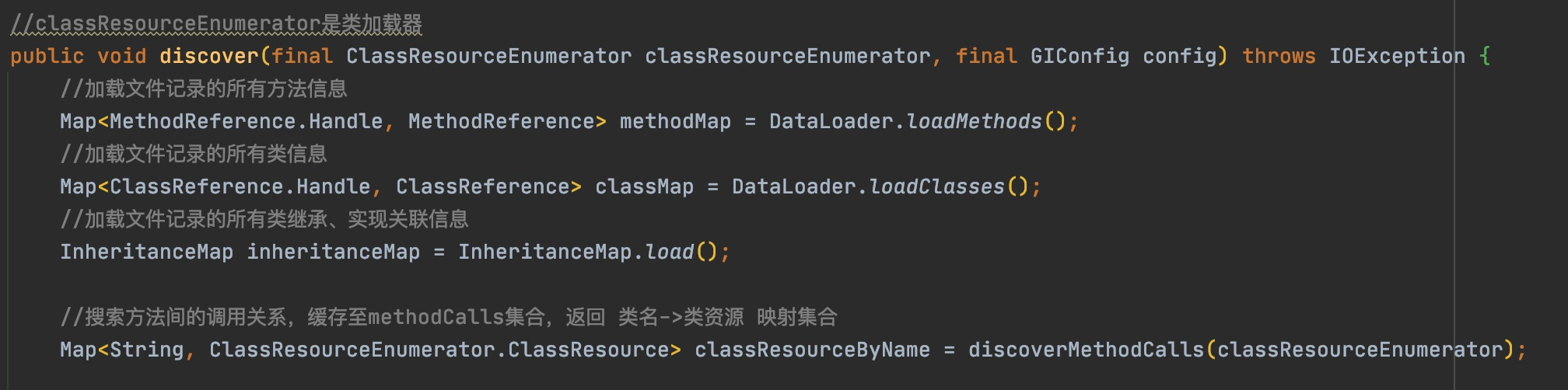
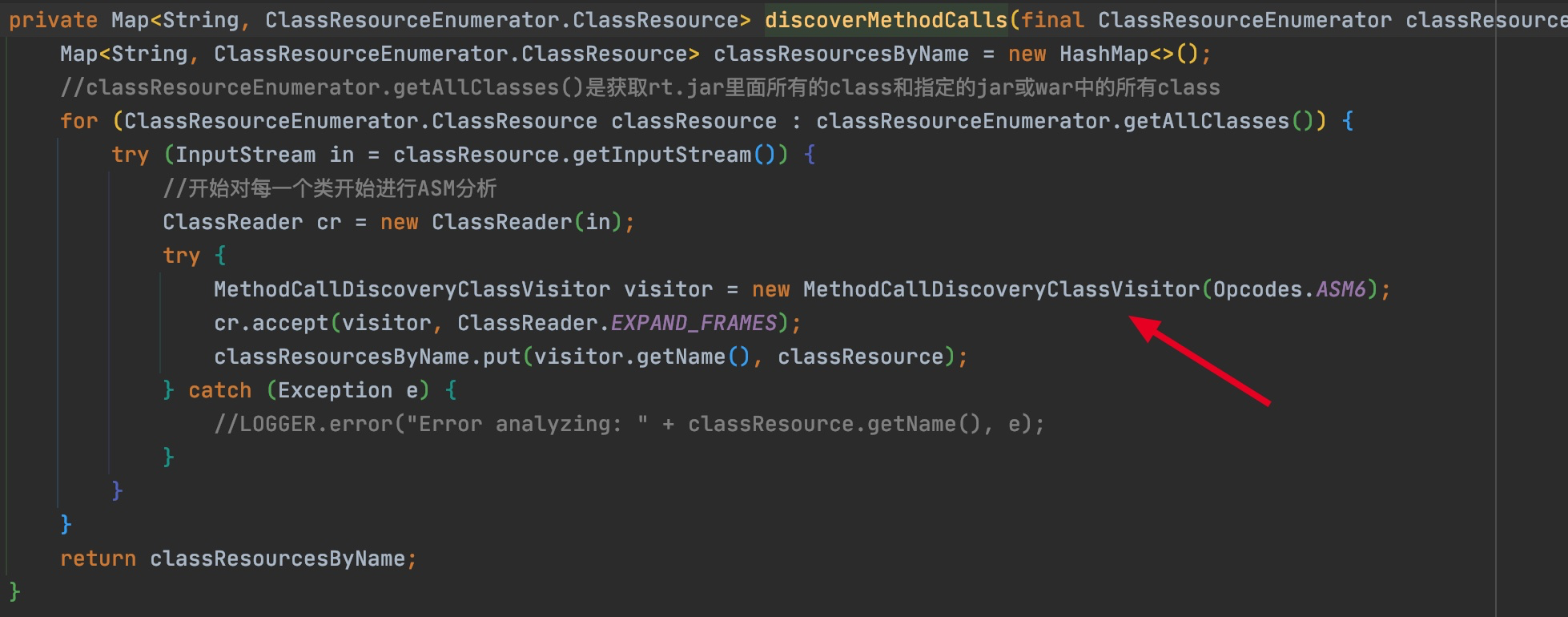
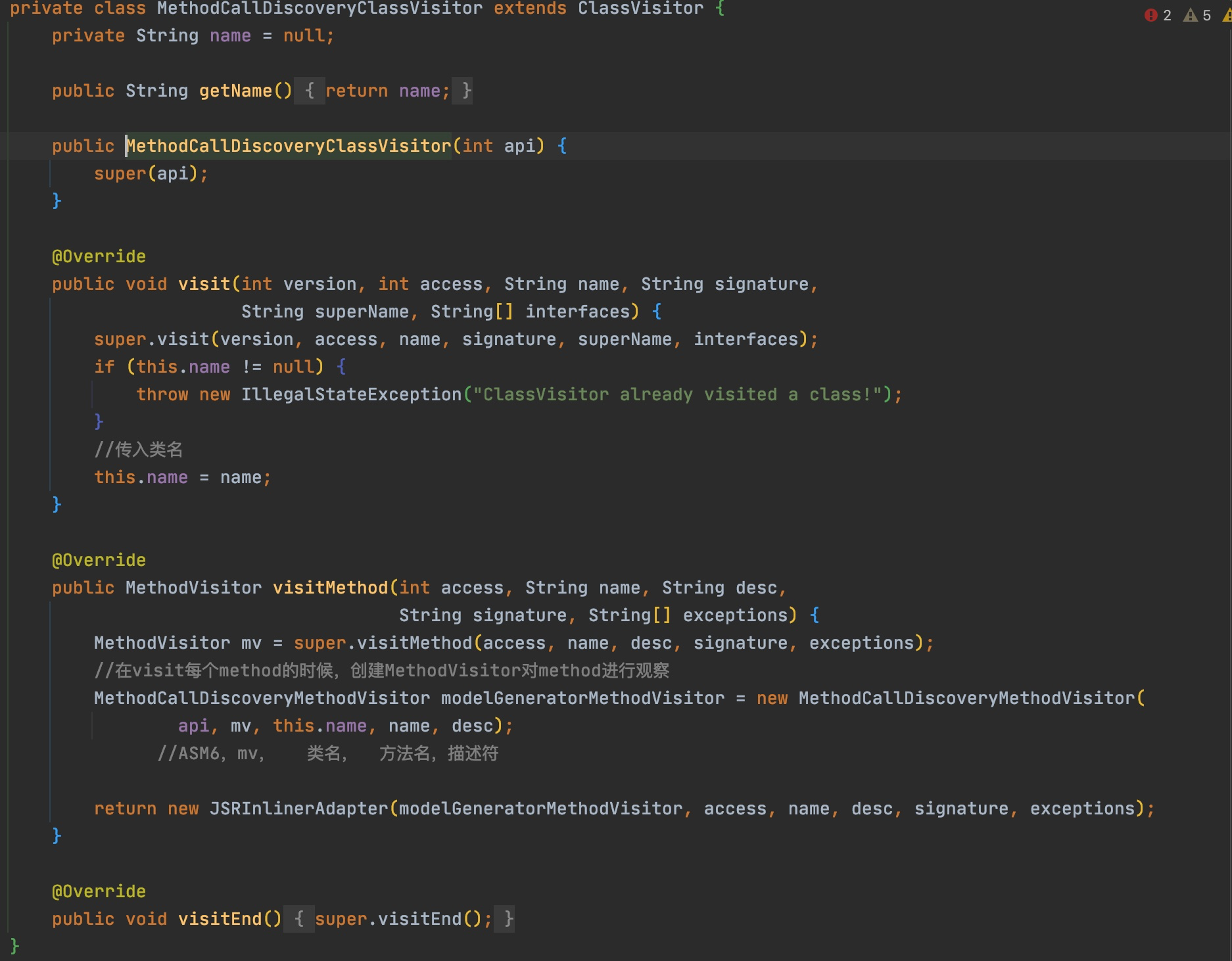
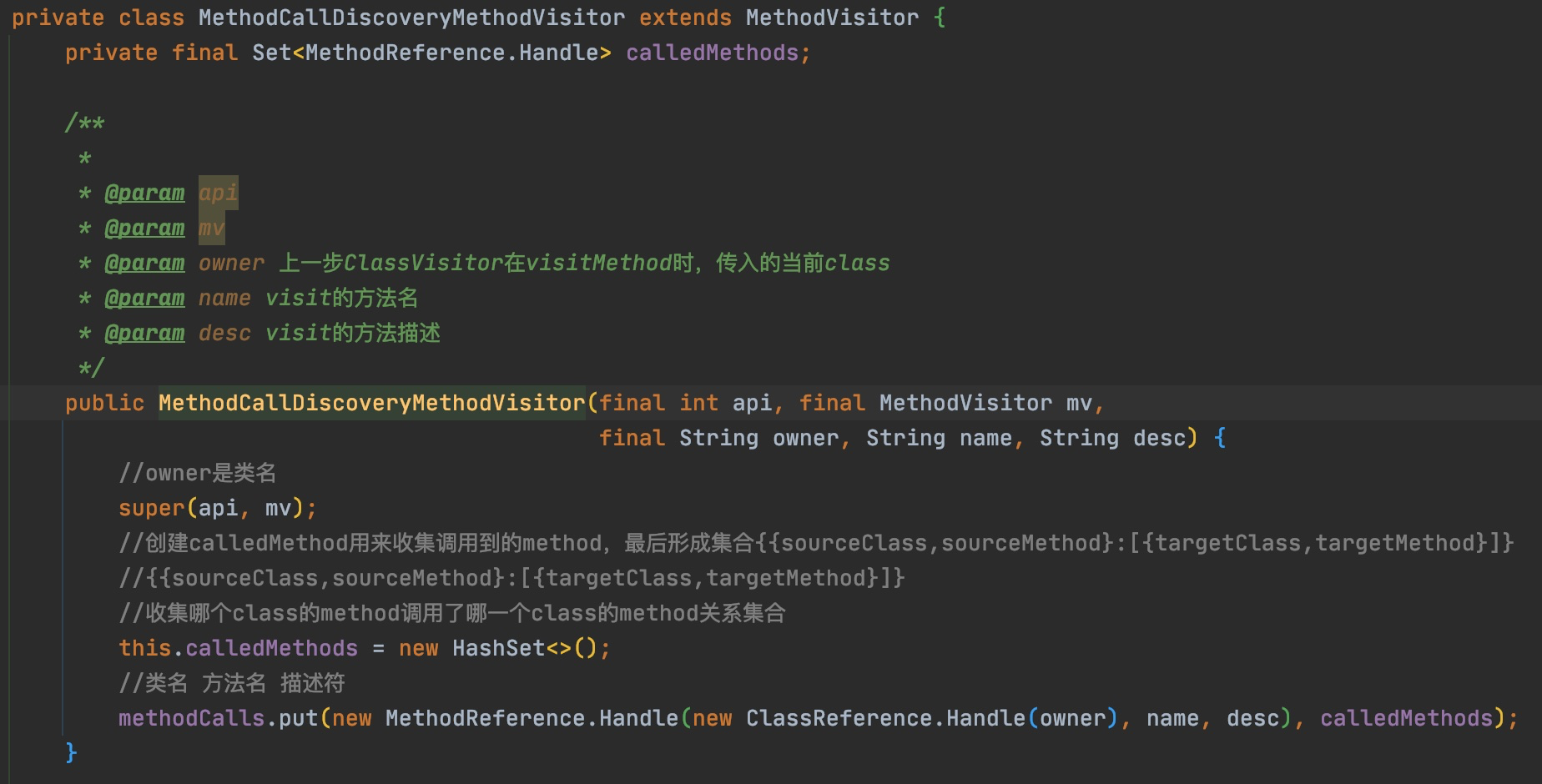
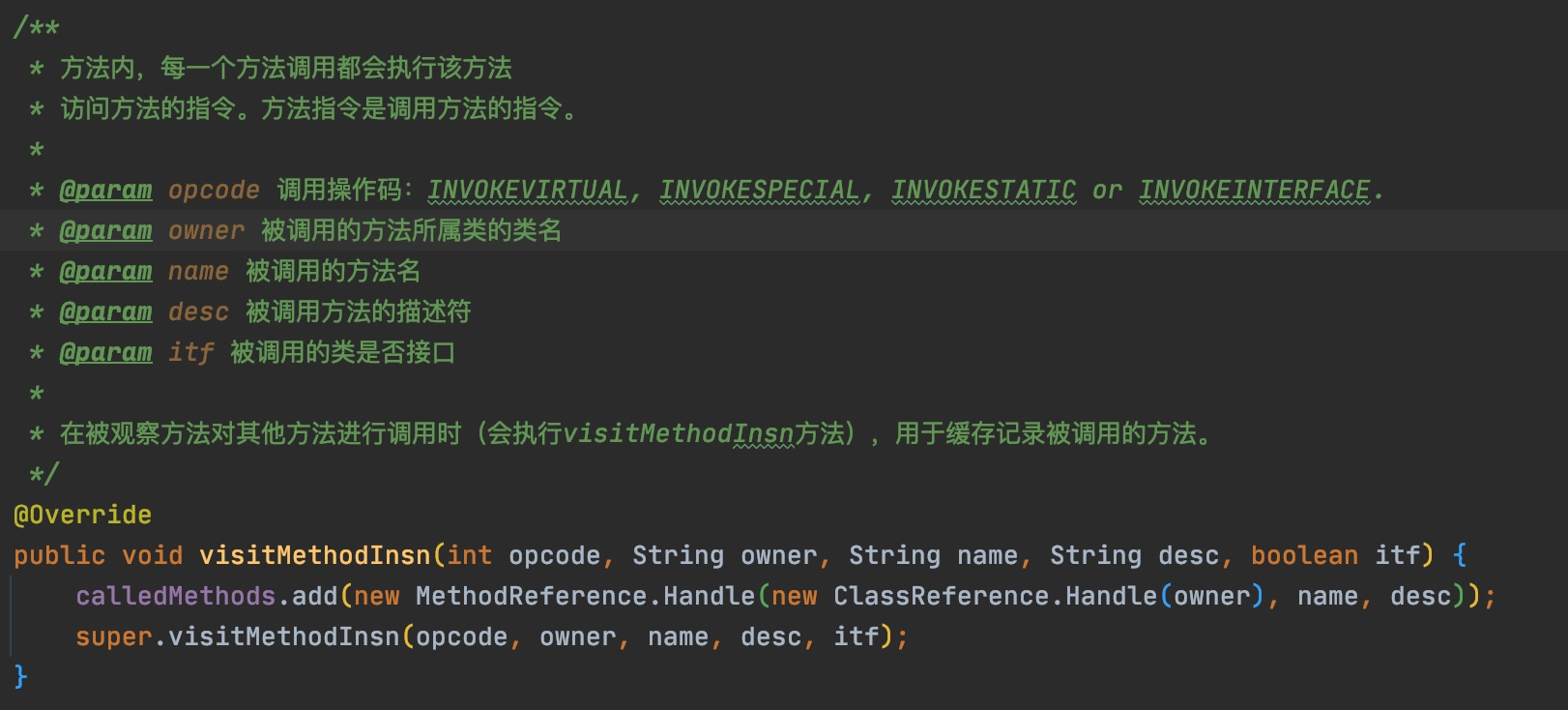
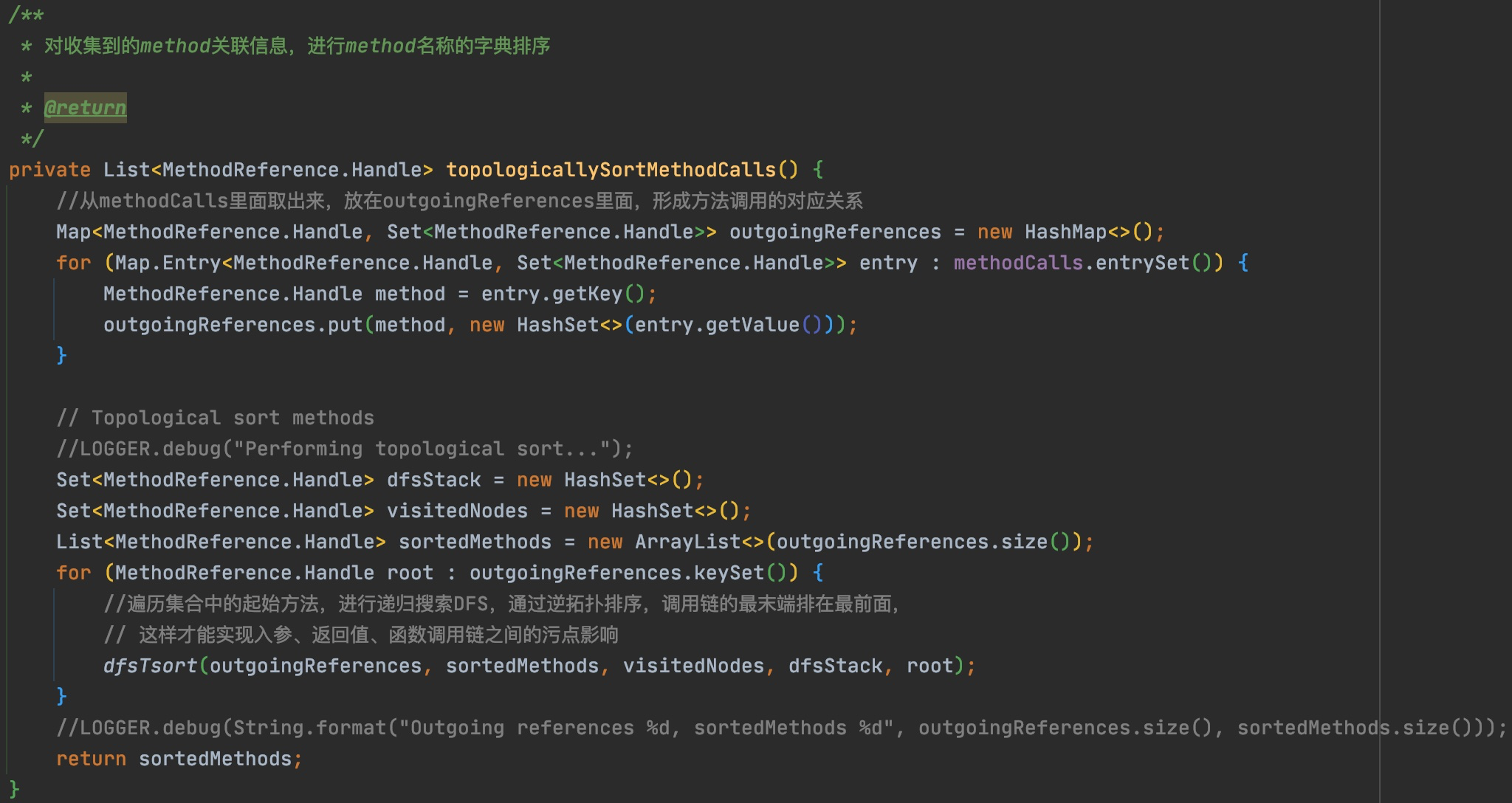
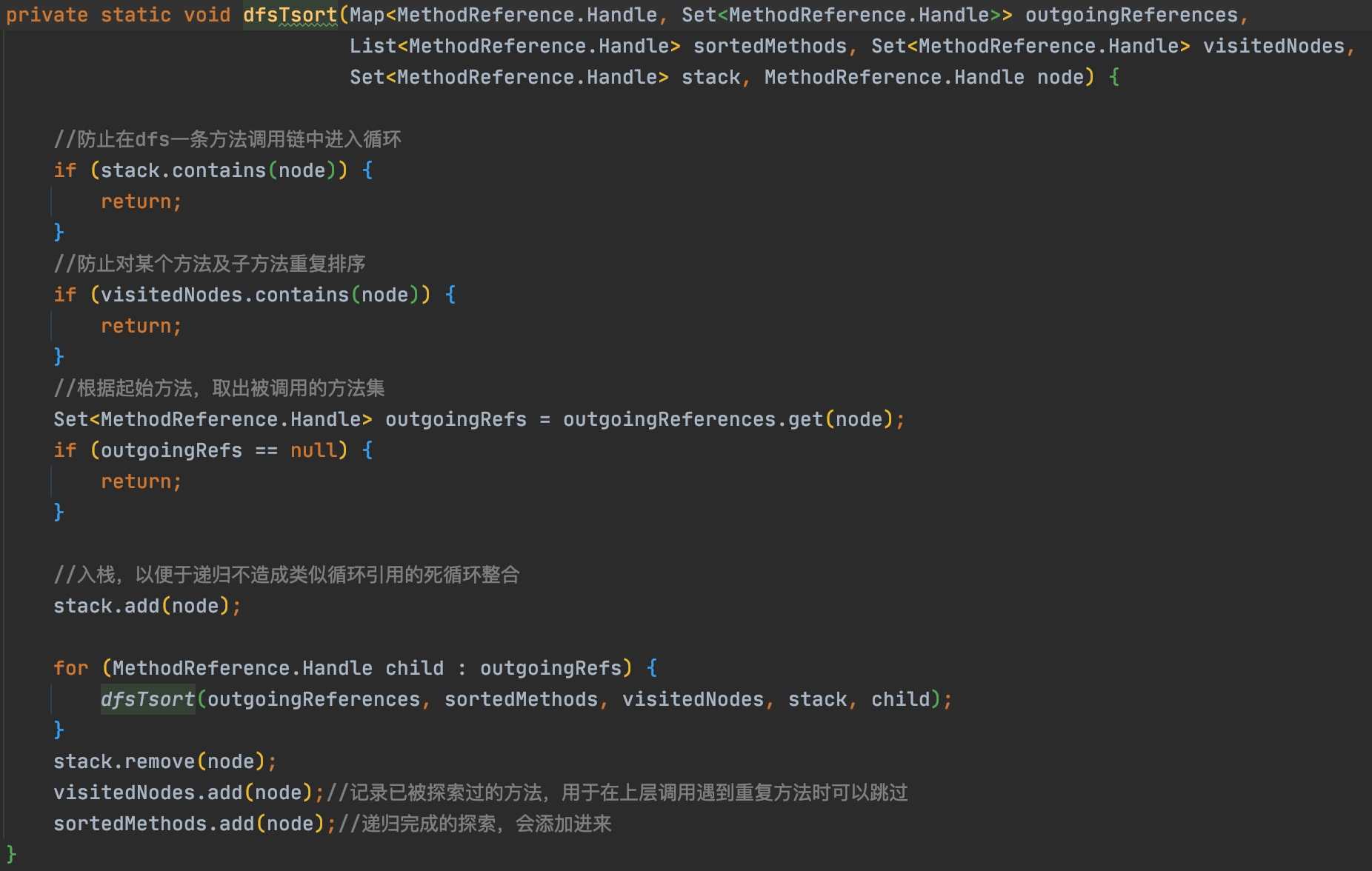
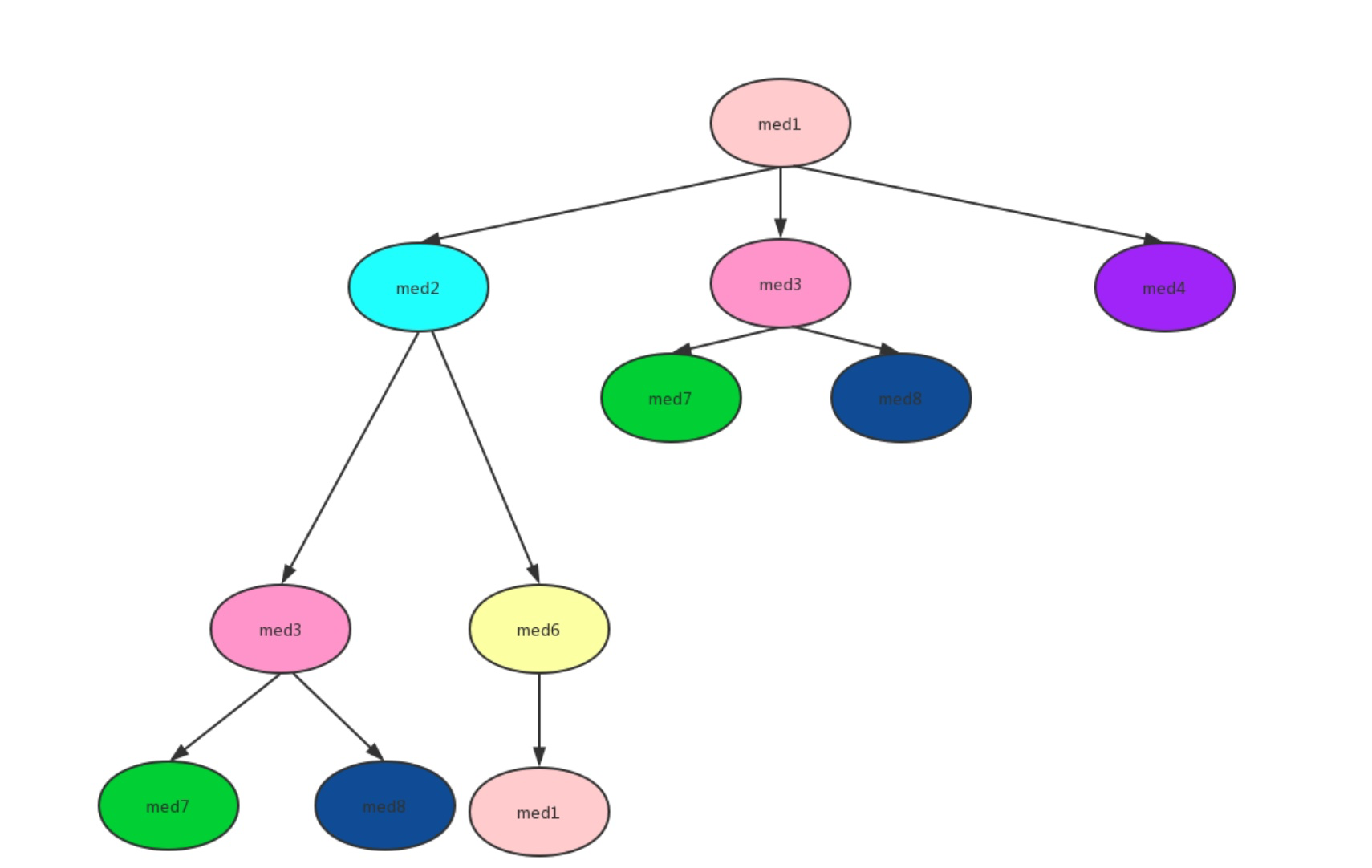
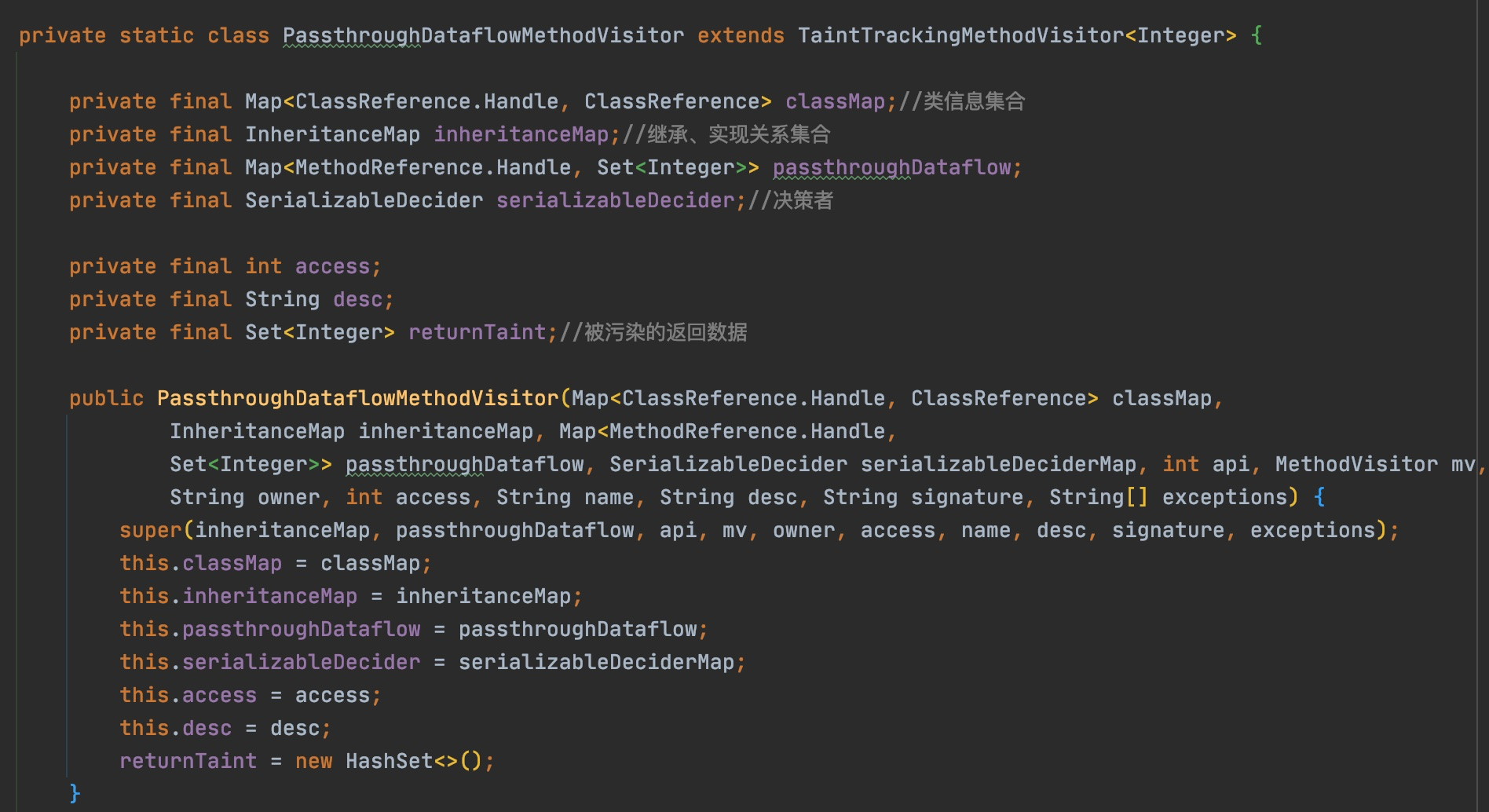
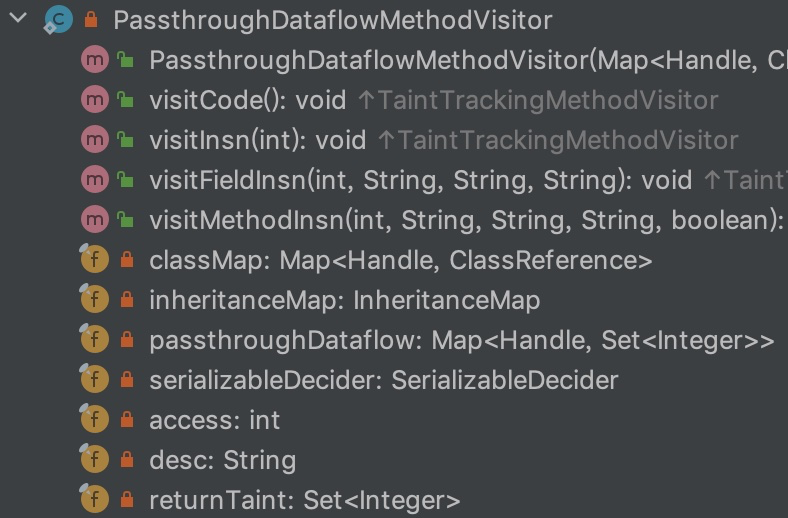
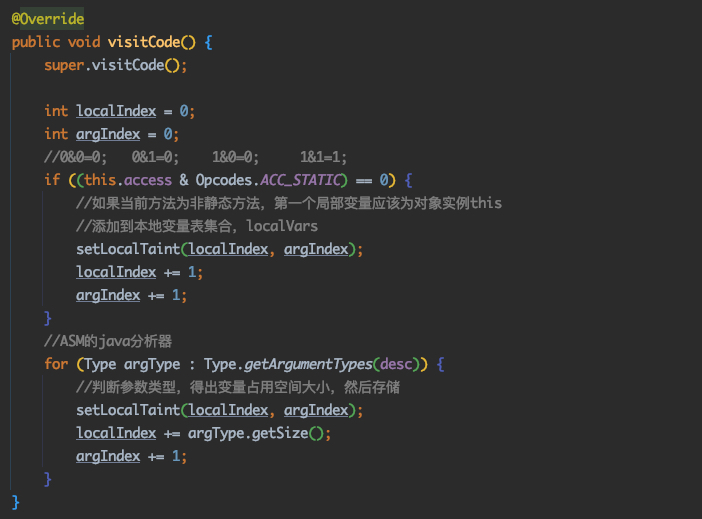
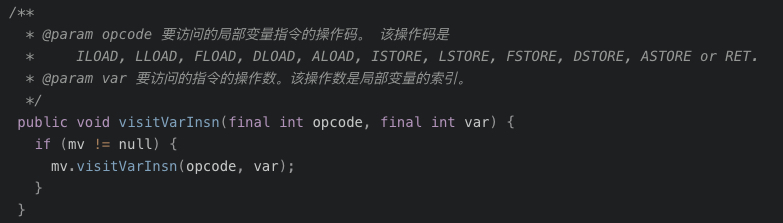
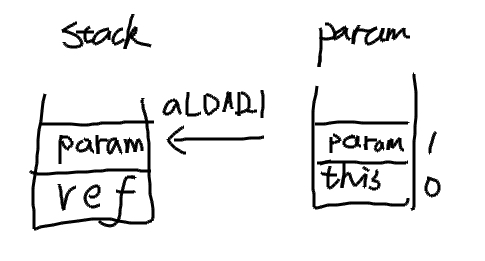
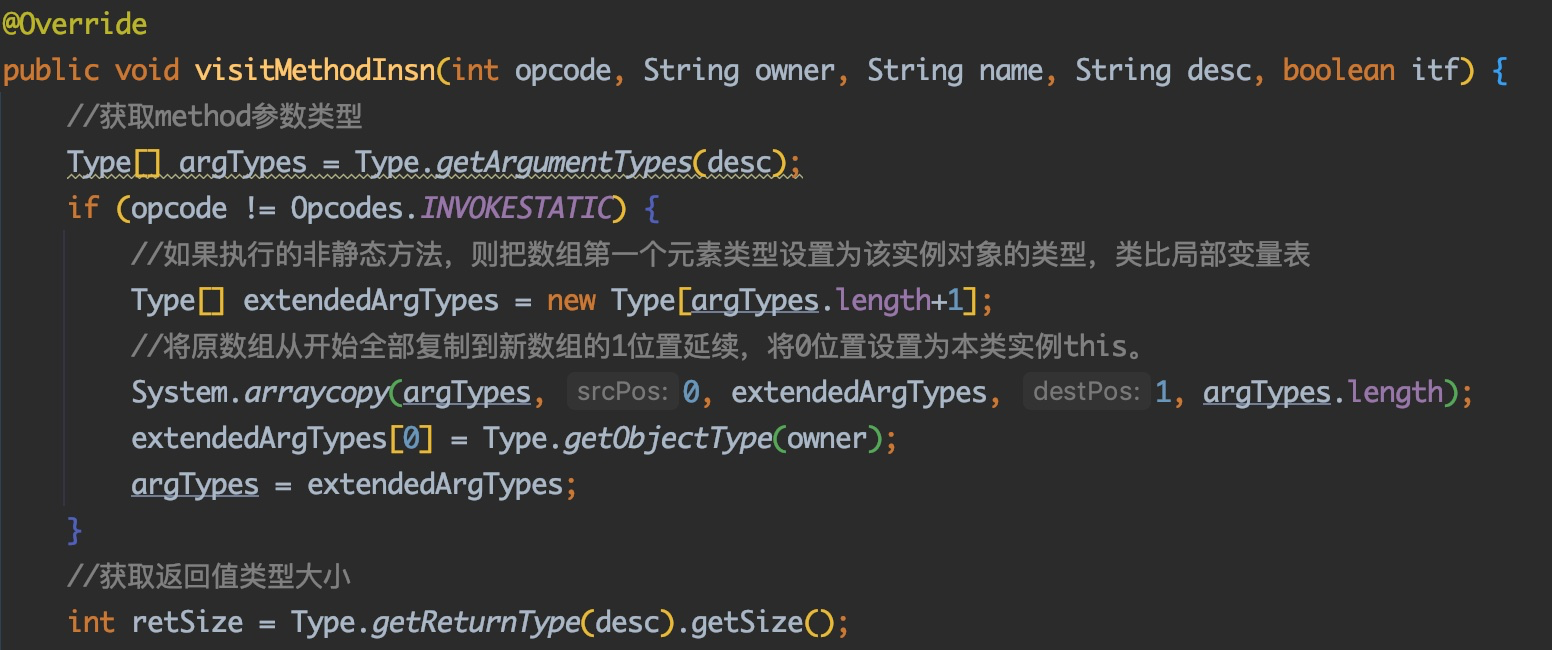
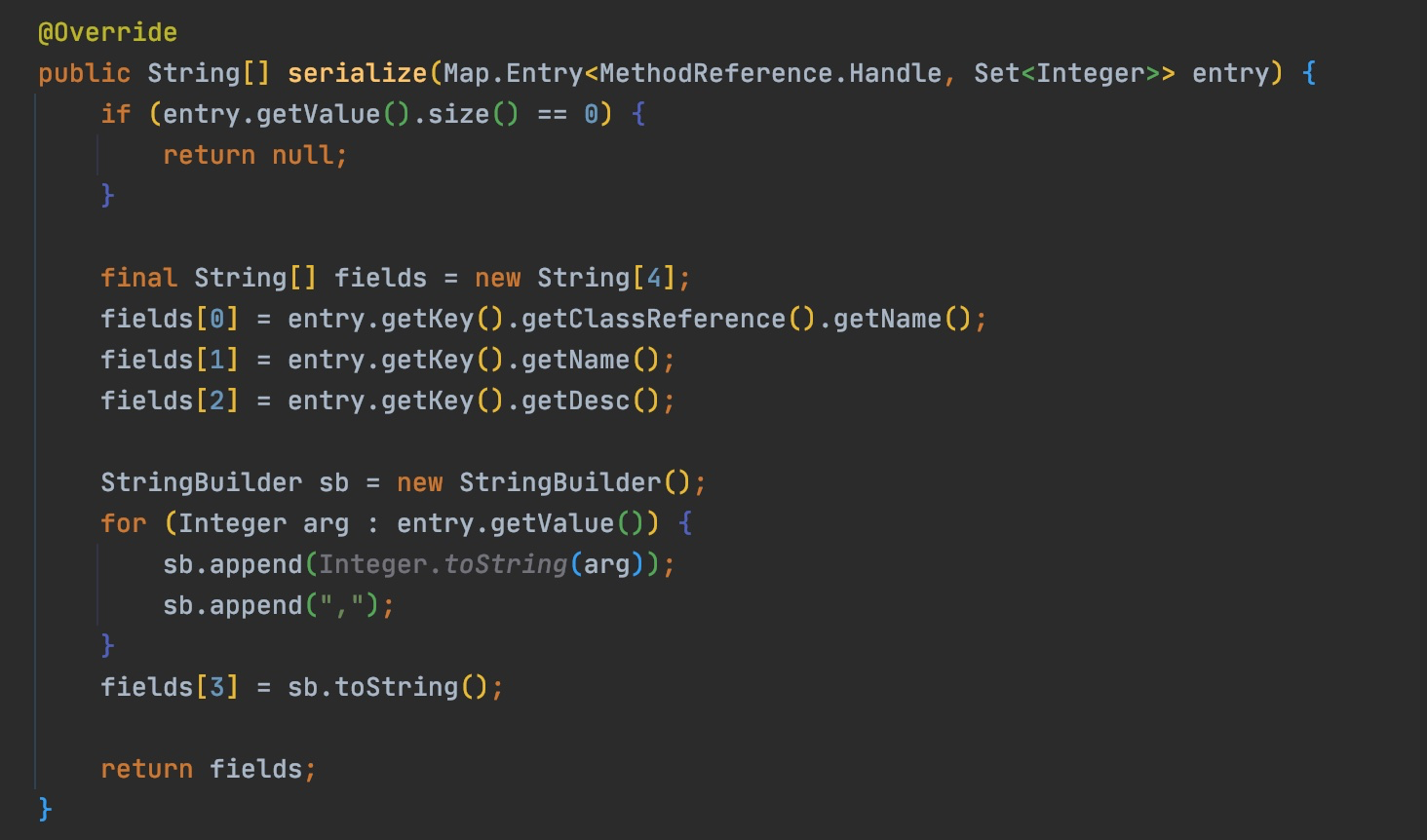
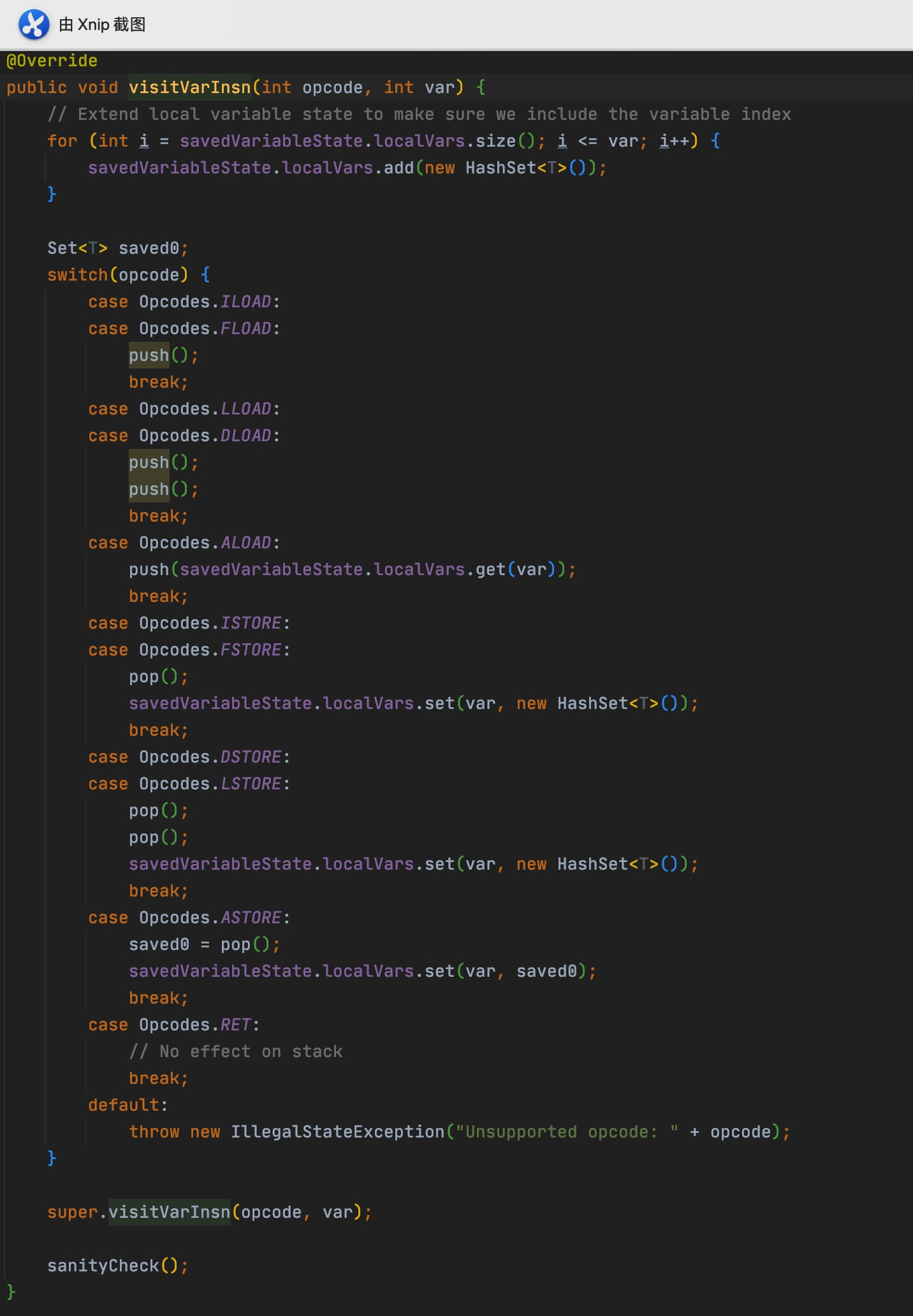
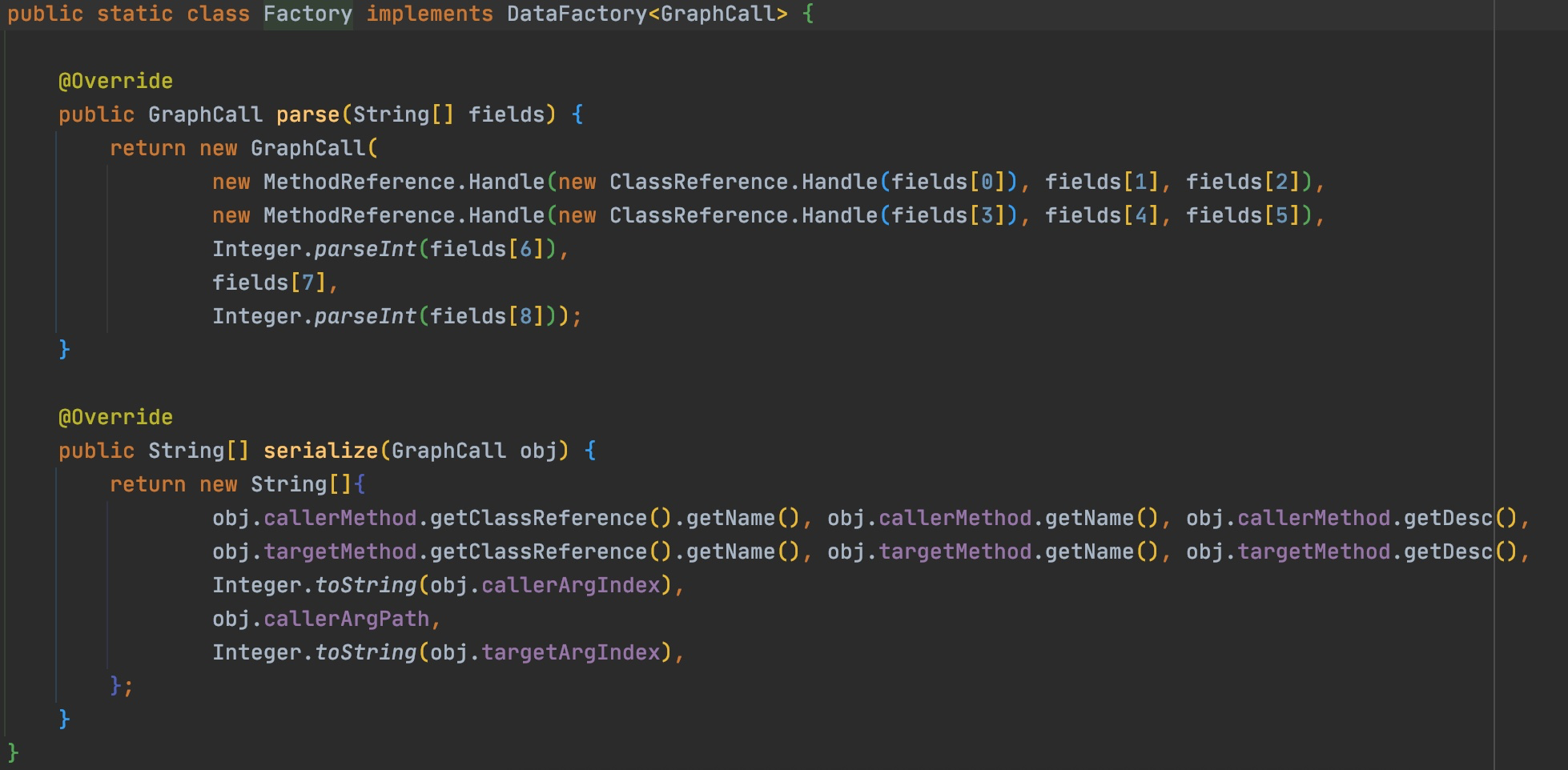
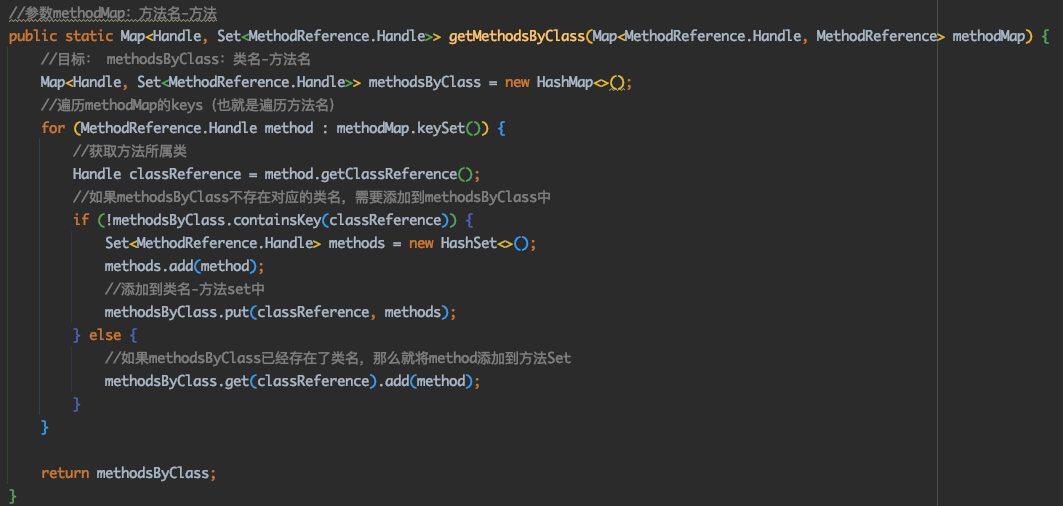
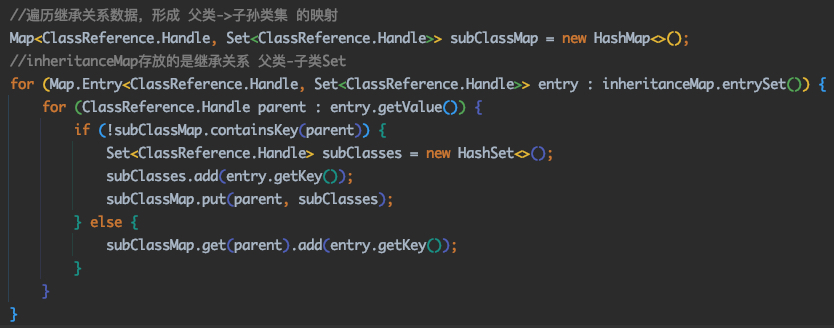
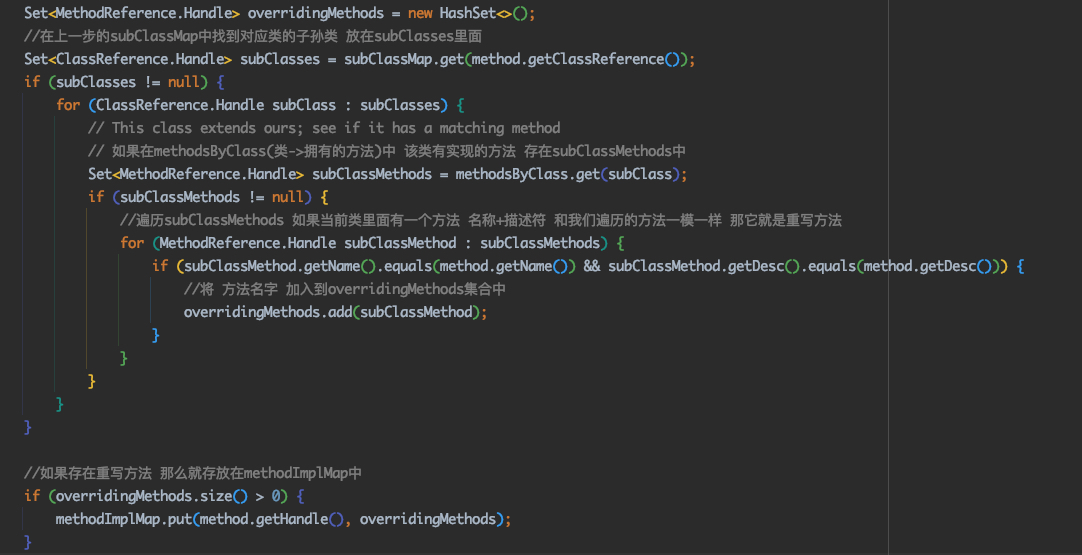
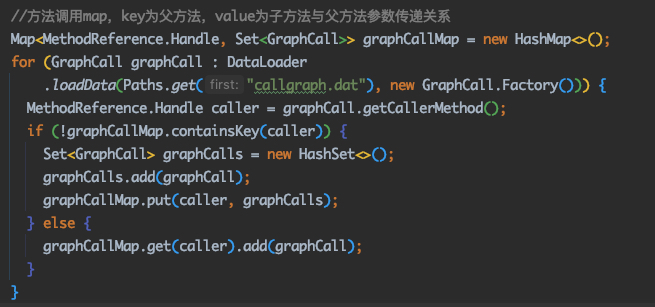
@Override publicvoidvisitVarInsn(int opcode, intvar){ // Extend local variable state to make sure we include the variable index for (int i = savedVariableState.localVars.size(); i <= var; i++) { savedVariableState.localVars.add(new HashSet<T>()); }
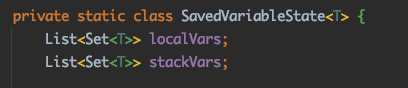
Set<T> saved0; switch(opcode) { case Opcodes.ILOAD: case Opcodes.FLOAD: push(); break; case Opcodes.LLOAD: case Opcodes.DLOAD: push(); push(); break; case Opcodes.ALOAD: push(savedVariableState.localVars.get(var)); break; case Opcodes.ISTORE: case Opcodes.FSTORE: pop(); savedVariableState.localVars.set(var, new HashSet<T>()); break; case Opcodes.DSTORE: case Opcodes.LSTORE: pop(); pop(); savedVariableState.localVars.set(var, new HashSet<T>()); break; case Opcodes.ASTORE: saved0 = pop(); savedVariableState.localVars.set(var, saved0); break; case Opcodes.RET: // No effect on stack break; default: thrownew IllegalStateException("Unsupported opcode: " + opcode); }
@Override publicvoidvisitInsn(int opcode){ switch(opcode) { case Opcodes.IRETURN://从当前方法返回int case Opcodes.FRETURN://从当前方法返回float case Opcodes.ARETURN://从当前方法返回对象引用 returnTaint.addAll(getStackTaint(0));//栈空间从内存高位到低位分配空间 break; case Opcodes.LRETURN://从当前方法返回long case Opcodes.DRETURN://从当前方法返回double returnTaint.addAll(getStackTaint(1)); break; case Opcodes.RETURN://从当前方法返回void break; default: break; }
调用者类名 调用者方法caller 调用者方法描述 被调用者类名 被调用者方法target 被调用者方法描述 调用者方法参数索引 调用者字段名 被调用者方法参数索引 Main (Ljava/lang/String;)V main A method1(Ljava/lang/String;)Ljava/lang/String; 11
switch (opcode) { case Opcodes.GETSTATIC: break; case Opcodes.PUTSTATIC: break; case Opcodes.GETFIELD: Type type = Type.getType(desc);//获取字段类型 if (type.getSize() == 1) { //size=1可能为引用类型 Boolean isTransient = null;
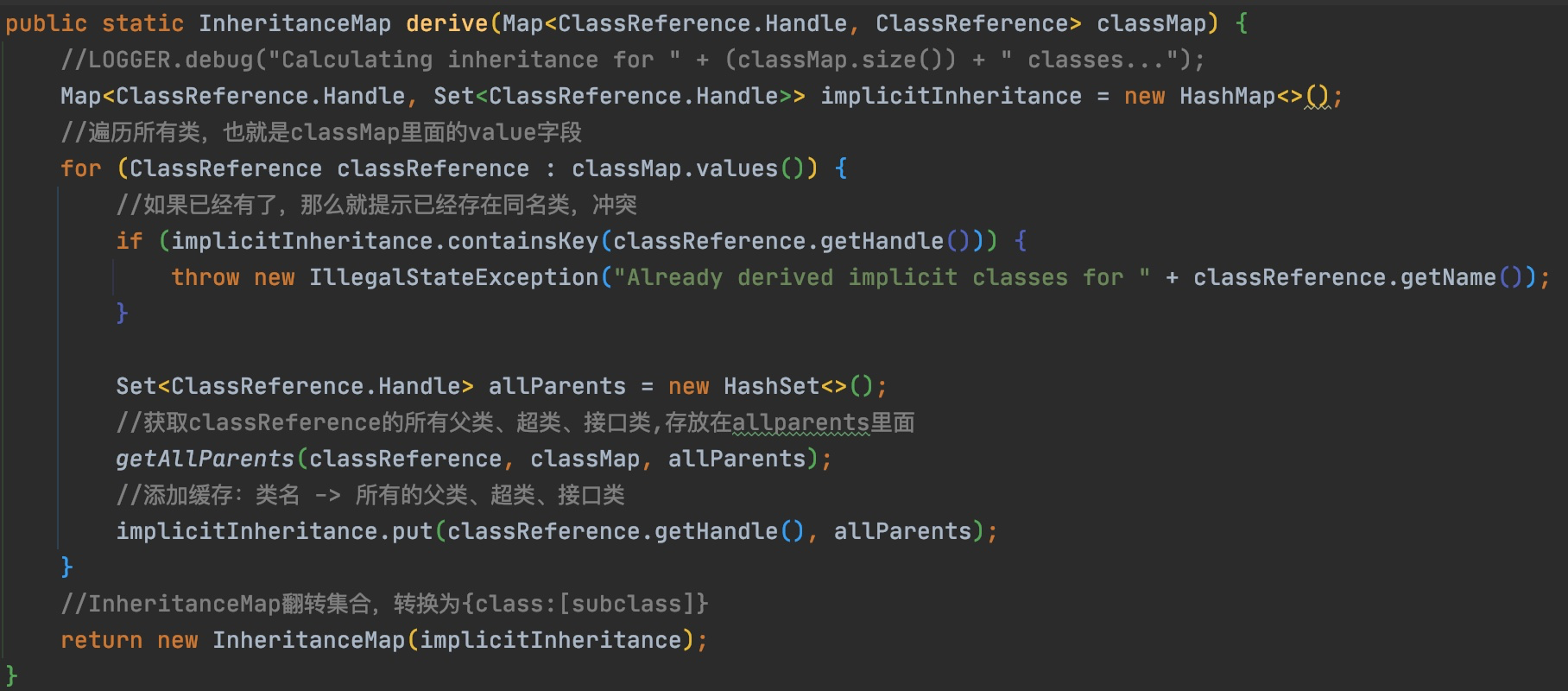
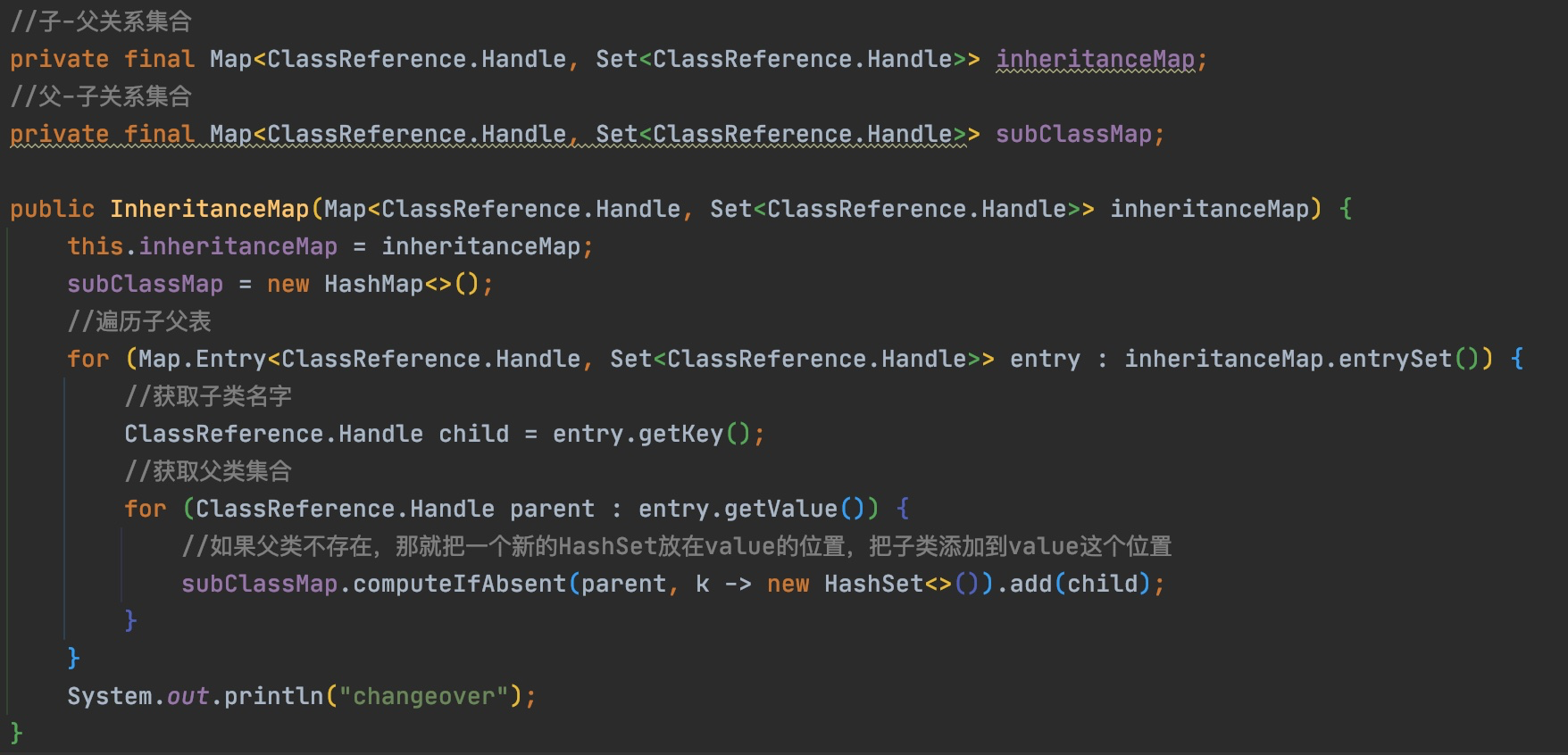
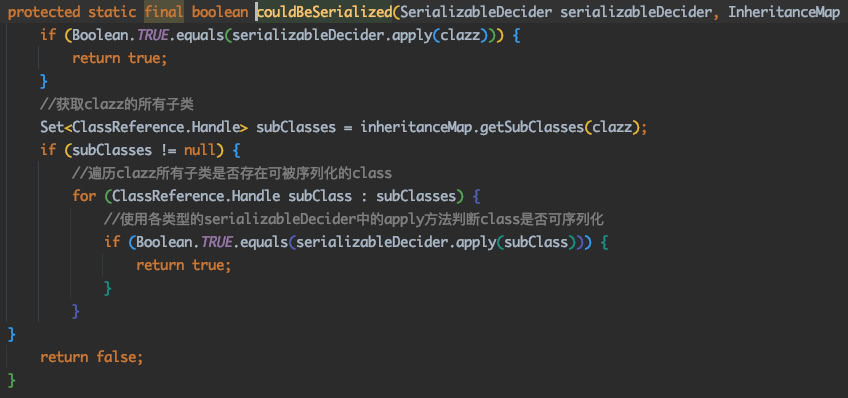
// If a field type could not possibly be serialized, it's effectively transient //判断调用的字段类型是否可序列化 if (!couldBeSerialized(serializableDecider, inheritanceMap, new ClassReference.Handle(type.getInternalName()))) { isTransient = Boolean.TRUE; } else { //若调用的字段可被序列化,则取当前类实例的所有字段,找出调用的字段,去判断是否被标识了transient ClassReference clazz = classMap.get(new ClassReference.Handle(owner)); while (clazz != null) { //遍历字段,判断是否是transient类型,以确定是否可被序列化 for (ClassReference.Member member : clazz.getMembers()) { if (member.getName().equals(name)) { isTransient = (member.getModifiers() & Opcodes.ACC_TRANSIENT) != 0; break; } } if (isTransient != null) { break; } //若找不到字段,则向上父类查找,继续遍历 clazz = classMap.get(new ClassReference.Handle(clazz.getSuperClass())); } }
Set<Integer> taint; if (!Boolean.TRUE.equals(isTransient)) { //若不是Transient字段,则从栈顶取出它,取出的是this或某实例变量,即字段所属实例 taint = getStackTaint(0); } else { taint = new HashSet<>(); }
调用者类名 调用者方法caller 调用者方法描述 被调用者类名 被调用者方法target 被调用者方法描述 调用者方法参数索引 调用者字段名 被调用者方法参数索引 Main (Ljava/lang/String;)V main A method1(Ljava/lang/String;)Ljava/lang/String; 11
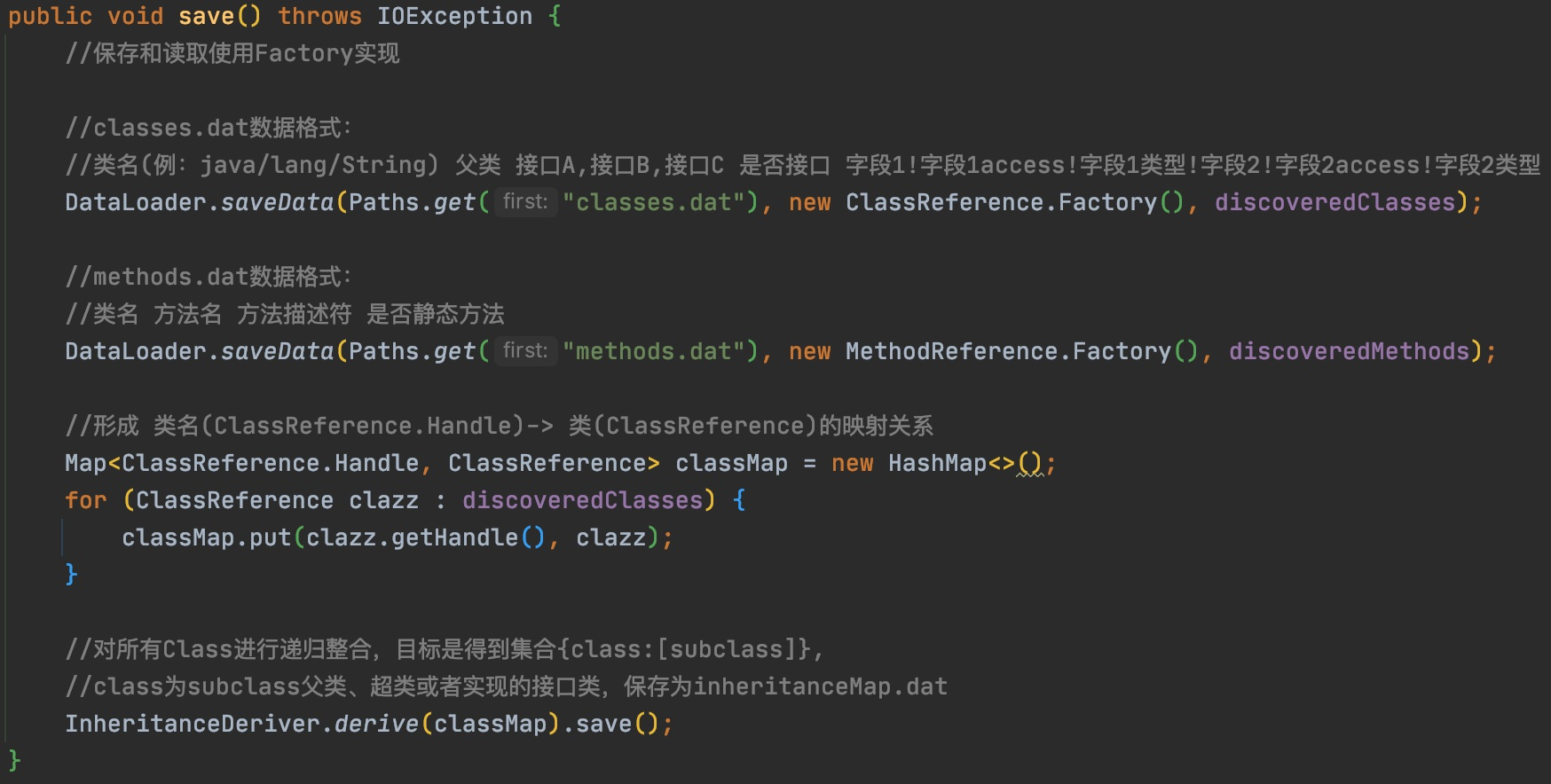
final SerializableDecider serializableDecider = new SimpleSerializableDecider(inheritanceMap);
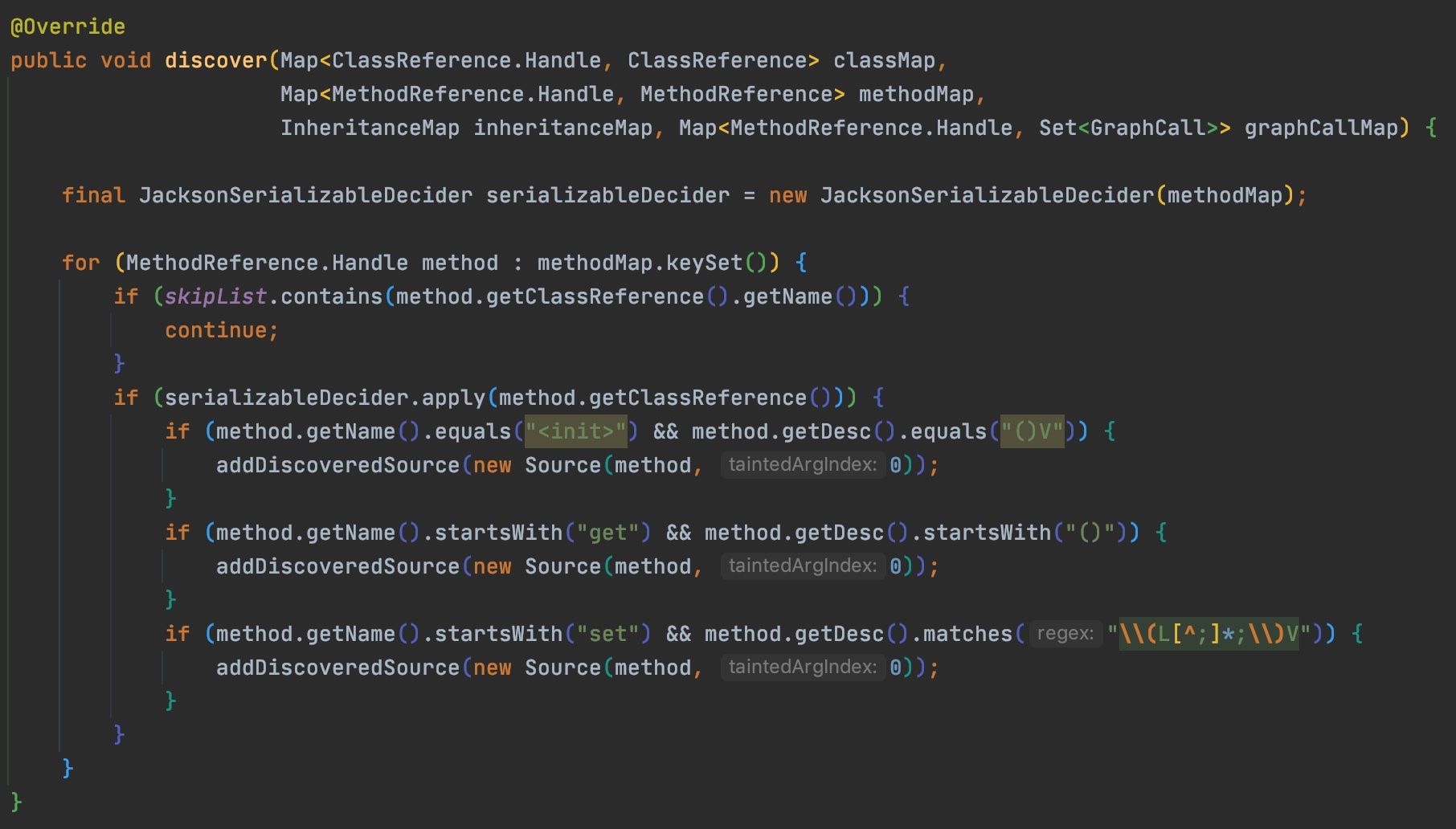
for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("finalize") && method.getDesc().equals("()V")) { addDiscoveredSource(new Source(method, 0)); } } }
// If a class implements readObject, the ObjectInputStream passed in is considered tainted // 如果类实现了readObject,则传入的ObjectInputStream被认为是污染的 for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("readObject") && method.getDesc().equals("(Ljava/io/ObjectInputStream;)V")) { addDiscoveredSource(new Source(method, 1)); } } }
// Using the proxy trick, anything extending serializable and invocation handler is tainted. // 使用动态代理trick时,任何扩展了serializable and InvocationHandler的类会受到污染。 for (ClassReference.Handle clazz : classMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(clazz)) && inheritanceMap.isSubclassOf(clazz, new ClassReference.Handle("java/lang/reflect/InvocationHandler"))) { MethodReference.Handle method = new MethodReference.Handle( clazz, "invoke", "(Ljava/lang/Object;Ljava/lang/reflect/Method;[Ljava/lang/Object;)Ljava/lang/Object;");
addDiscoveredSource(new Source(method, 0)); } }
// hashCode() or equals() are accessible entry points using standard tricks of putting those objects into a HashMap. // hashCode()或equals()是将对象放入HashMap的标准技巧的可访问入口点 for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("hashCode") && method.getDesc().equals("()I")) { addDiscoveredSource(new Source(method, 0)); } if (method.getName().equals("equals") && method.getDesc().equals("(Ljava/lang/Object;)Z")) { addDiscoveredSource(new Source(method, 0)); addDiscoveredSource(new Source(method, 1)); } } }
// Using a comparator proxy, we can jump into the call() / doCall() method of any groovy Closure and all the // args are tainted. // 使用比较器代理,可以跳转到任何groovy Closure的call()/doCall()方法,所有的args都被污染 // https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/Groovy1.java for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference())) && inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/Closure")) && (method.getName().equals("call") || method.getName().equals("doCall"))) {
addDiscoveredSource(new Source(method, 0)); Type[] methodArgs = Type.getArgumentTypes(method.getDesc()); for (int i = 0; i < methodArgs.length; i++) { addDiscoveredSource(new Source(method, i + 1)); } } } }
privatebooleanisSink(MethodReference.Handle method, int argIndex, InheritanceMap inheritanceMap){ if (method.getClassReference().getName().equals("java/io/FileInputStream") && method.getName().equals("<init>")) { returntrue; } if (method.getClassReference().getName().equals("java/io/FileOutputStream") && method.getName().equals("<init>")) { returntrue; } if (method.getClassReference().getName().equals("java/nio/file/Files") && (method.getName().equals("newInputStream") || method.getName().equals("newOutputStream") || method.getName().equals("newBufferedReader") || method.getName().equals("newBufferedWriter"))) { returntrue; } if (method.getClassReference().getName().equals("java/lang/Runtime") && method.getName().equals("exec")) { returntrue; } /* if (method.getClassReference().getName().equals("java/lang/Class") && method.getName().equals("forName")) { return true; } if (method.getClassReference().getName().equals("java/lang/Class") && method.getName().equals("getMethod")) { return true; } */ // If we can invoke an arbitrary method, that's probably interesting (though this doesn't assert that we // can control its arguments). Conversely, if we can control the arguments to an invocation but not what // method is being invoked, we don't mark that as interesting. if (method.getClassReference().getName().equals("java/lang/reflect/Method") && method.getName().equals("invoke") && argIndex == 0) { returntrue; } if (method.getClassReference().getName().equals("java/net/URLClassLoader") && method.getName().equals("newInstance")) { returntrue; } if (method.getClassReference().getName().equals("java/lang/System") && method.getName().equals("exit")) { returntrue; } if (method.getClassReference().getName().equals("java/lang/Shutdown") && method.getName().equals("exit")) { returntrue; } if (method.getClassReference().getName().equals("java/lang/Runtime") && method.getName().equals("exit")) { returntrue; } if (method.getClassReference().getName().equals("java/nio/file/Files") && method.getName().equals("newOutputStream")) { returntrue; } if (method.getClassReference().getName().equals("java/lang/ProcessBuilder") && method.getName().equals("<init>") && argIndex > 0) { returntrue; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/lang/ClassLoader")) && method.getName().equals("<init>")) { returntrue; } if (method.getClassReference().getName().equals("java/net/URL") && method.getName().equals("openStream")) { returntrue; } // Some groovy-specific sinks if (method.getClassReference().getName().equals("org/codehaus/groovy/runtime/InvokerHelper") && method.getName().equals("invokeMethod") && argIndex == 1) { returntrue; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/MetaClass")) && Arrays.asList("invokeMethod", "invokeConstructor", "invokeStaticMethod").contains(method.getName())) { returntrue; } returnfalse; }