序言
浮云游子意,落日故人情。
梳理Java序列化流程。
参考panda 师傅。
写在前面 Java序列化就是将对象写入到I/O流之中,通常输出格式为.ser文件。
简单说首先创建一个ObjectOutputStream输出流对象,然后调用ObjectOutputStream对象的writeObject方法,按照规范格式输出可序列化对象。
具体流程 接下来一步一步走,消化一遍panda 师傅的文章。
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Serialize public static class Demo implements Serializable private String string; transient String name = "hello" ; public Demo (String s) this .string = s; } public static void main (String[] args) throws IOException Demo demo = new Demo("panda" ); ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("panda.out" )); outputStream.writeObject(new Demo("panda" )); outputStream.close(); } } }
构造函数 1 2 ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("panda.out" )); outputStream.writeObject(new Demo("panda" ));
首先来到public ObjectOutputStream(OutputStream out)构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ObjectOutputStream (OutputStream out) throws IOException verifySubclass(); bout = new BlockDataOutputStream(out); handles = new HandleTable(10 , (float ) 3.00 ); subs = new ReplaceTable(10 , (float ) 3.00 ); enableOverride = false ; writeStreamHeader(); bout.setBlockDataMode(true ); if (extendedDebugInfo) { debugInfoStack = new DebugTraceInfoStack(); } else { debugInfoStack = null ; } }
一头雾水,接下来一步一步梳理:
verifySubclass()方法:
验证本类(或其子类)实例可以在不违反安全约束的情况下被构造出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private void verifySubclass () Class<?> cl = getClass(); if (cl == ObjectOutputStream.class ) return ; SecurityManager sm = System.getSecurityManager(); if (sm == null ) return ; processQueue(Caches.subclassAuditsQueue, Caches.subclassAudits); WeakClassKey key = new WeakClassKey(cl, Caches.subclassAuditsQueue); Boolean result = Caches.subclassAudits.get(key); if (result == null ) { result = Boolean.valueOf(auditSubclass(cl)); Caches.subclassAudits.putIfAbsent(key, result); } if (result.booleanValue()) return ; sm.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION); }
接下来可以看到对bout,handles,subs,enableOverride一些成员变量进行了复制,跳到他们的声明处看一看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private final BlockDataOutputStream bout;private final HandleTable handles;private final ReplaceTable subs;private int protocol = PROTOCOL_VERSION_2;private int depth;private byte [] primVals;private final boolean enableOverride;private boolean enableReplace;
重点挑这几个说:
bout:用来处理数据块转换的数据流,理解为一个容器
handles :对象->handle引用
subs: 对象->替换对象
enableOverride:布尔值 用来决定在序列化Java对象时选用writeObjectOverride方法还是writeObject方法 通常为false
关于 handles 的作用,举个例子,我们知道 Java 序列化除了保存字段信息外,还保存有类信息 ,当同一个对象序列化两次时第二次只用保存第一次的编号,这样可以大大减少序列化文件的大小。
你肯定对第一个bout的理解有些别扭。
开启支线任务,什么是BlockDataOutputStream ?
BlockDataOutputStream BlockDataOutputStream是ObjectOutputStream的一个重要内部类,这个类负责将缓冲区中的数据写入到字节流 。
该类部分内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 /** * Buffered output stream with two modes: in default mode, outputs data in * same format as DataOutputStream; in "block data" mode, outputs data * bracketed by block data markers (see object serialization specification * for details). */ private static class BlockDataOutputStream extends OutputStream implements DataOutput { /** maximum data block length */ private static final int MAX_BLOCK_SIZE = 1024; /** maximum data block header length */ private static final int MAX_HEADER_SIZE = 5; /** (tunable) length of char buffer (for writing strings) */ private static final int CHAR_BUF_SIZE = 256; /** buffer for writing general/block data */ private final byte[] buf = new byte[MAX_BLOCK_SIZE]; /** buffer for writing block data headers */ private final byte[] hbuf = new byte[MAX_HEADER_SIZE]; /** char buffer for fast string writes */ private final char[] cbuf = new char[CHAR_BUF_SIZE]; /** block data mode */ private boolean blkmode = false; /** current offset into buf */ private int pos = 0; /** underlying output stream */ private final OutputStream out; /** loopback stream (for data writes that span data blocks) */ private final DataOutputStream dout; /** * Creates new BlockDataOutputStream on top of given underlying stream. * Block data mode is turned off by default. */ BlockDataOutputStream(OutputStream out) { this.out = out; dout = new DataOutputStream(this); } ... }
大致意思就是:
缓冲输出流有两种模式:
在默认模式下,以与DataOutputStream相同的格式输出数据;
在 “块数据 “模式下,输出数据 在 “块数据 “模式下,输出由块数据标记括起来的数据 – 详见对象序列化规范。
可以理解成BlockDataOutputStream类是封装后的DataOutputStream类,并且提供了一些缓冲区及成员属性。
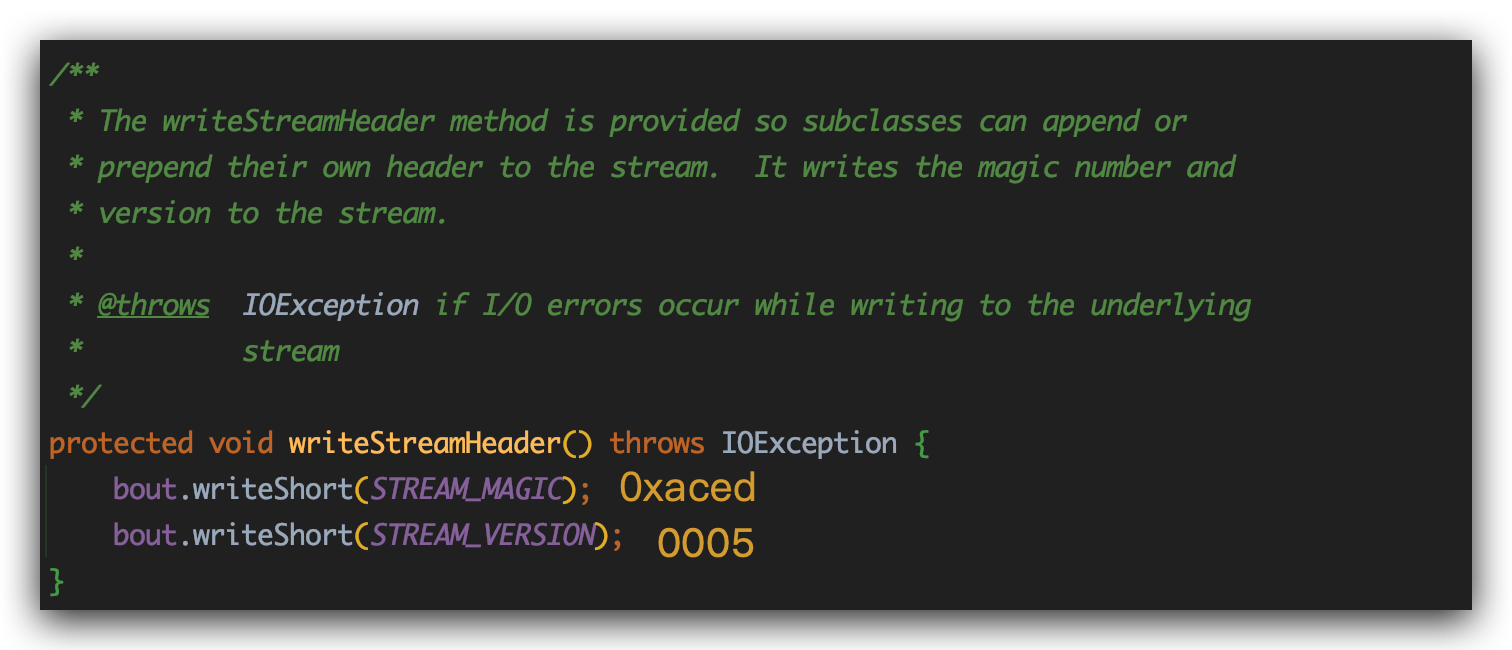
在给这些成员变量赋值结束之后,接下来进入writeStreamHeader方法。
熟悉的aced0005出现了,可以理解为bout就是我们的句柄,负责缓存我们的序列化数据。
接下来是bout.setBlockDataMode(true); 将bout设置为块模式
核心:writeObject 构造函数执行结束之后,就要来到第二句话:outputStream.writeObject(new Demo("panda"));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public final void writeObject (Object obj) throws IOException if (enableOverride) { writeObjectOverride(obj); return ; } try { writeObject0(obj, false ); } catch (IOException ex) { if (depth == 0 ) { writeFatalException(ex); } throw ex; } }
可以说;writeObject 将所有序列委托给了 writeObject0 完成,如果序列化出现异常调用 writeFatalException 方法。
首先是if(enableOverride) ,这里面的enableOverride其实一般都是false(上一步的构造函数),那么就直接进入到writeObject0方法:
核中核 :writeObject0 writeObject0 比较复杂,大致可分为三个部分:
一是判断需不需要序列化;
二是判断是否替换了对象;
三是终于可以序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 private void writeObject0 (Object obj, boolean unshared) throws IOException boolean oldMode = bout.setBlockDataMode(false ); depth++; try { int h; if ((obj = subs.lookup(obj)) == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } Object orig = obj; Class<?> cl = obj.getClass(); ObjectStreamClass desc; for (;;) { Class<?> repCl; desc = ObjectStreamClass.lookup(cl, true ); if (!desc.hasWriteReplaceMethod() || (obj = desc.invokeWriteReplace(obj)) == null || (repCl = obj.getClass()) == cl) { break ; } cl = repCl; } if (enableReplace) { Object rep = replaceObject(obj); if (rep != obj && rep != null ) { cl = rep.getClass(); desc = ObjectStreamClass.lookup(cl, true ); } obj = rep; } if (obj != orig) { subs.assign(orig, obj); if (obj == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } } if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else { if (extendedDebugInfo) { throw new NotSerializableException( cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } } } finally { depth--; bout.setBlockDataMode(oldMode); } }
首先第一步就把bout的块模式关掉了,原始模式赋值给了oldMode。
1 boolean oldMode = bout.setBlockDataMode(false );
下一句depth++:表示的是对象序列化的深度。
比如说对象A进行了序列化,那么depth++;
此时如果A中的字段(field)也是一个对象,需要对这个对象再次进行序列化,此时再一次depth++;
细心的可以发现其实在最后的finally里面配套的有depth–;
因而如果不出异常则 depth 最终会是 0,有异常则在 catch 模块时 depth 不为 0。
接下来按照三步走的顺序来解析writeObject0做了什么:
第一步:处理已经处理过的和不可替换的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int h;if ((obj = subs.lookup(obj)) == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; }
已经处理过的 和不可替换的 对象,这些都是不能够序列化的,其实在大多数情况下,我们的代码都不会进入第一步代码块。
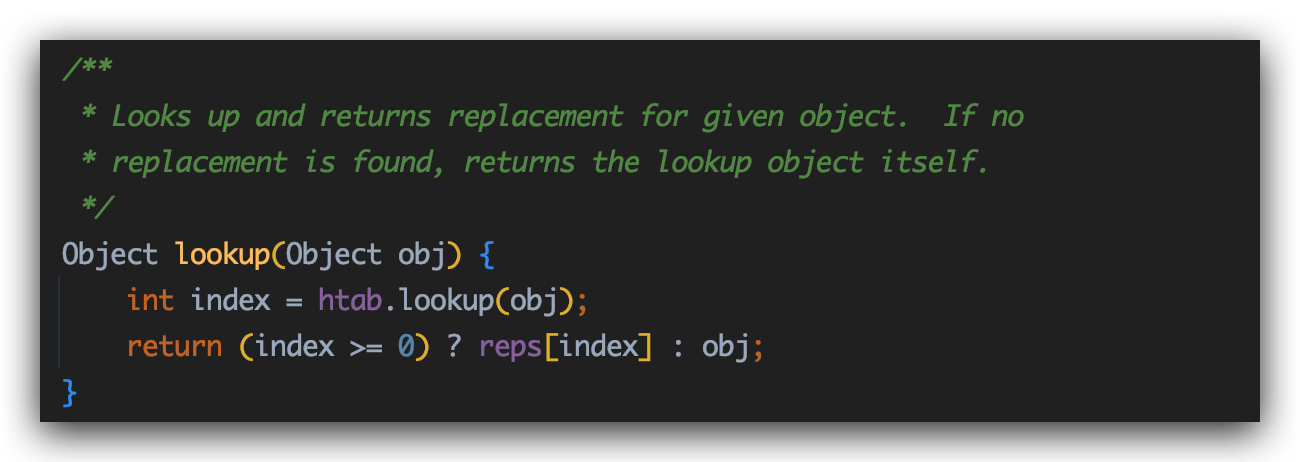
首先进入if ((obj = subs.lookup(obj)) == null)这句:
lookup方法会在subs这个map中当前对象obj是否有可替换(writeReplace)对象,如果没有的话,则返回obj对象本身。
也就是说,这个方法实际上就是处理以前写入的对象和不可替换的对象。更直白点的意思,这段代码实际上做的是一个检测功能,如果检测到当前传入对象在 替换哈希表(ReplaceTable) 中无法找到,那么就调用writeNull方法。
下一个if判断是判断当前写入方式是不是“unshared”方式,然后可以看到紧跟着的就是handles.lookup(obj),跟进去:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int lookup (Object obj) if (size == 0 ) { return -1 ; } int index = hash(obj) % spine.length; for (int i = spine[index]; i >= 0 ; i = next[i]) { if (objs[i] == obj) { return i; } } return -1 ; }
该方法会查找并返回与给定对象关联的handler,如果没有找到映射,则返回 -1;
直白的意思就是说判断是否在“引用哈希表(HandleTable)”中找到该引用,如果有,那么调用writeHandle方法并且返回;如果没找到,那么返回-1,需要进一步序列化处理。
接下来判断当前传入对象是不是特殊类型的Class和ObjectStreamClass,如果是,则调用writeClass或writeClassDesc方法并且返回;
总结1: Java 序列化保存了很多与数据无关的数据,如类信息 。但 Java 本身也做了一些优化,如 handles 保存了类的句柄,这样重复的类就只用保存一个句柄就可以了。
第二步:查找可替换对象是否已经序列化了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 Object orig = obj; Class<?> cl = obj.getClass(); ObjectStreamClass desc; for (;;) { Class<?> repCl; desc = ObjectStreamClass.lookup(cl, true ); if (!desc.hasWriteReplaceMethod() || (obj = desc.invokeWriteReplace(obj)) == null || (repCl = obj.getClass()) == cl) { break ; } cl = repCl; } if (enableReplace) { Object rep = replaceObject(obj); if (rep != obj && rep != null ) { cl = rep.getClass(); desc = ObjectStreamClass.lookup(cl, true ); } obj = rep; } if (obj != orig) { subs.assign(orig, obj); if (obj == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } }
可以看到是一个for无条件循环,重点是desc = ObjectStreamClass.lookup(cl, true);
这个方法很长,概括一下就是:
ObjectStreamClass.lookup()封装待序列化的类生成类描述符 (返回ObjectStreamClass类型) ,获取包括类名、自定义serialVersionUID、可序列化字段 (返回ObjectStreamField类型) 和构造方法,以及writeObject、readObject方法等
desc更像是一个类信息模板,需要查找类信息的时候,desc充当句柄。
一步步看,一开始检查是否开启了enableReplace标志位,通常为false,不会进来。
1 2 3 4 5 6 7 8 if (enableReplace) { Object rep = replaceObject(obj); if (rep != obj && rep != null ) { cl = rep.getClass(); desc = ObjectStreamClass.lookup(cl, true ); } obj = rep; }
再往下,如果对象是被替换的,则第二次进行原始检查:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (obj != orig) { subs.assign(orig, obj); if (obj == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } }
如果对象被替换,这里会对原始对象进行二次检查,和最开始的那段代码很像,这里先将替换对象插入到subs(替换哈希表)中,然后进行类似的判断。
第三步:序列化对象
以上执行都完成过后,会处理剩余对象类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else { if (extendedDebugInfo) { throw new NotSerializableException( cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } }
Switch-case模式:
如果对象是String类型,那么调用writeString方法将数据写入字节流;
如果对象是Array类型,那么调用writeArray方法将数据写入字节流;
如果对象为Enum类型,调用writeEnum方法将数据写入字节流;
如果对象实现了Serializable接口,调用writeOrdinaryObject方法将数据写入字节流;
以上条件都不满足时则抛出NotSerializableException异常信息;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private void writeString (String str, boolean unshared) throws IOException handles.assign(unshared ? null : str); long utflen = bout.getUTFLength(str); if (utflen <= 0xFFFF ) { bout.writeByte(TC_STRING); bout.writeUTF(str, utflen); } else { bout.writeByte(TC_LONGSTRING); bout.writeLongUTF(str, utflen); } } private void writeEnum (Enum<?> en, ObjectStreamClass desc, boolean unshared) throws IOException bout.writeByte(TC_ENUM); ObjectStreamClass sdesc = desc.getSuperDesc(); writeClassDesc((sdesc.forClass() == Enum.class) ? desc : sdesc, false); handles.assign(unshared ? null : en); writeString(en.name(), false ); } private void writeOrdinaryObject (Object obj, ObjectStreamClass desc, boolean unshared) throws IOException desc.checkSerialize(); bout.writeByte(TC_OBJECT); writeClassDesc(desc, false ); handles.assign(unshared ? null : obj); if (desc.isExternalizable() && !desc.isProxy()) { writeExternalData((Externalizable) obj); } else { writeSerialData(obj, desc); } }
前面三个大同小异,panda师傅简单的举例了一下writeString方法:
1 2 3 4 5 6 7 8 9 10 11 private void writeString (String str, boolean unshared) throws IOException handles.assign(unshared ? null : str); long utflen = bout.getUTFLength(str); if (utflen <= 0xFFFF ) { bout.writeByte(TC_STRING); bout.writeUTF(str, utflen); } else { bout.writeByte(TC_LONGSTRING); bout.writeLongUTF(str, utflen); } }
首先在写入String对象之前,代码会判断当前写入方式是否是unshared,如果不是unshared方式还需要在handles这个对象映射表中插入当前String对象;接着,代码会调用getUTFLength函数获取String字符串的长度和0xFFFF比较,如果大于该值时,表示当前String对象是一个长字符串对象,那么会先写入TC_LONGSTRING标记(表示是LONGSTRING类型数据),然后写入字符串的长度和内容;如果小于等于该值时,表示当前String对象就是一个普通的字符串对象,那么会先写入TC_STRING标记(表示是一个STRING类型对象),然后写入字符串的长度和内容。
writeOrdinaryObject 终于到了重点分析的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private void writeOrdinaryObject (Object obj, ObjectStreamClass desc, boolean unshared) throws IOException if (extendedDebugInfo) { debugInfoStack.push( (depth == 1 ? "root " : "" ) + "object (class \"" + obj.getClass().getName() + "\", " + obj.toString() + ")" ); } try { desc.checkSerialize(); bout.writeByte(TC_OBJECT); writeClassDesc(desc, false ); handles.assign(unshared ? null : obj); if (desc.isExternalizable() && !desc.isProxy()) { writeExternalData((Externalizable) obj); } else { writeSerialData(obj, desc); } } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } }
首先来到desc.checkSerialize();,desc其实就是类描述信息,判断当前对象是否是可以被序列化的,也就是是否实现了Serializable接口。
如果是一个可序列化对象,那么会开始写入TC_OBJECT标记(表示开始序列化操作),随后调用writeClassDesc方法写入当前对象所属类的类描述信息,跟进去:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void writeClassDesc (ObjectStreamClass desc, boolean unshared) throws IOException int handle; if (desc == null ) { writeNull(); } else if (!unshared && (handle = handles.lookup(desc)) != -1 ) { writeHandle(handle); } else if (desc.isProxy()) { writeProxyDesc(desc, unshared); } else { writeNonProxyDesc(desc, unshared); } }
writeClassDesc方法主要用于判断当前的类描述符使用什么方式写入:
如果传入的类描述信息是一个null,那么会调用writeNull方法;
如果没有使用unshared方式,并且可以在handles对象池中找到传入的对象信息,说明类信息已经序列化,那么调用writeHandle保存句柄即可;
如果传入的类是一个动态代理类,那么调用writeProxyDesc方法;
如果上面三个条件都不满足,那么调用writeNonProxyDesc方法。
跟进writeNonProxyDesc(desc, unshared)这里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private void writeNonProxyDesc (ObjectStreamClass desc, boolean unshared) throws IOException bout.writeByte(TC_CLASSDESC); handles.assign(unshared ? null : desc); if (protocol == PROTOCOL_VERSION_1) { desc.writeNonProxy(this ); } else { writeClassDescriptor(desc); } Class<?> cl = desc.forClass(); bout.setBlockDataMode(true ); if (cl != null && isCustomSubclass()) { ReflectUtil.checkPackageAccess(cl); } annotateClass(cl); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); writeClassDesc(desc.getSuperDesc(), false ); }
首先写入TC_CLASSDESC标记(表新类描述信息的开始)信息,然后判断使用的模式是unshared模式,那么将desc所表示的类元数据信息 插入到handles对象的映射表中,然后根据使用的流协议版本调用不同的write方法,如果使用的流协议是PROTOCOL_VERSION_1,那么直接调用desc成员的writeNonProxy方法,并且将当前引用this作为实参传入到writeNonProxy方法中,如果使用的不是PROTOCOL_VERSION_1协议,那么会调用当前类中的writeClassDescriptor方法。
1 2 3 4 protected void writeClassDescriptor (ObjectStreamClass desc) throws IOException desc.writeNonProxy(this ); }
继续跟进writeNonProxy中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void writeNonProxy (ObjectOutputStream out) throws IOException out.writeUTF(name); out.writeLong(getSerialVersionUID()); byte flags = 0 ; if (externalizable) { flags |= ObjectStreamConstants.SC_EXTERNALIZABLE; int protocol = out.getProtocolVersion(); if (protocol != ObjectStreamConstants.PROTOCOL_VERSION_1) { flags |= ObjectStreamConstants.SC_BLOCK_DATA; } } else if (serializable) { flags |= ObjectStreamConstants.SC_SERIALIZABLE; } if (hasWriteObjectData) { flags |= ObjectStreamConstants.SC_WRITE_METHOD; } if (isEnum) { flags |= ObjectStreamConstants.SC_ENUM; } out.writeByte(flags); out.writeShort(fields.length); for (int i = 0 ; i < fields.length; i++) { ObjectStreamField f = fields[i]; out.writeByte(f.getTypeCode()); out.writeUTF(f.getName()); if (!f.isPrimitive()) { out.writeTypeString(f.getTypeString()); } } }
先调用writeUTF方法写入类名 到字节流(bout),这里的类名是类全名,带了包名的那种(out.writeUTF(name);)
再调用writeLong方法写入serialVersionUID的值到字节流(out.writeLong(getSerialVersionUID());)
然后开始写入当前类中成员属性的数量信息到字节流(out.writeShort(fields.length);)
最后会写入每一个字段的信息,这里的字段信息包含三部分内容:TypeCode、fieldName、fieldType
1 2 3 4 5 6 7 8 9 10 ... out.writeShort(fields.length); for (int i = 0 ; i < fields.length; i++) { ObjectStreamField f = fields[i]; out.writeByte(f.getTypeCode()); out.writeUTF(f.getName()); if (!f.isPrimitive()) { out.writeTypeString(f.getTypeString()); } }
到这里writeClassDescriptor就走完了,回到上一层,发现又打开了块模式bout.setBlockDataMode(true);
再往下会调用annotateClass(cl); 但是跟进去发现什么都没有(迷
在调用annotateClass方法完成过后,代码会关闭Data Block模式,然后写入TC_ENDBLOCKDATA标记(表示当前非动态代理类的描述信息的终止)。
到这里,writeNonProxy和writeClassDescriptor流程结束 ,同样,也导致writeClassDesc流程结束 ,并且回到writeOrdinaryObject方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private void writeOrdinaryObject (Object obj, ObjectStreamClass desc, boolean unshared) throws IOException if (extendedDebugInfo) { debugInfoStack.push( (depth == 1 ? "root " : "" ) + "object (class \"" + obj.getClass().getName() + "\", " + obj.toString() + ")" ); } try { desc.checkSerialize(); bout.writeByte(TC_OBJECT); writeClassDesc(desc, false ); handles.assign(unshared ? null : obj); if (desc.isExternalizable() && !desc.isProxy()) { writeExternalData((Externalizable) obj); } else { writeSerialData(obj, desc); } } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } }
接下来来到handles.assign(unshared ? null : obj); 这里如果使用的模式是unshared模式,则将desc所表示的类元数据信息插入到handles对象的映射表中,最后会判断当前Java对象的序列化语义,如果当前对象不是一个动态代理类 并且是实现了外部化 的,则调用writeExternalData方法写入对象信息,如果当前对象是一个实现了Serializable接口的,则调用writeSerialData方法写入对象信息。
接下来将类数据信息序列化,写入bout,进入writeSerialData函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 private void writeSerialData (Object obj, ObjectStreamClass desc) throws IOException ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout(); for (int i = 0 ; i < slots.length; i++) { ObjectStreamClass slotDesc = slots[i].desc; if (slotDesc.hasWriteObjectMethod()) { PutFieldImpl oldPut = curPut; curPut = null ; SerialCallbackContext oldContext = curContext; if (extendedDebugInfo) { debugInfoStack.push( "custom writeObject data (class \"" + slotDesc.getName() + "\")" ); } try { curContext = new SerialCallbackContext(obj, slotDesc); bout.setBlockDataMode(true ); slotDesc.invokeWriteObject(obj, this ); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); } finally { curContext.setUsed(); curContext = oldContext; if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; } else { defaultWriteFields(obj, slotDesc); } } }
就像注释说的一样,会为给定对象的每个可序列化的类写入实例数据,从父类到子类。
再这个方法内会首先判断当前使用的字节流协议,如果使用的是PROTOCOL_VERSION_1协议,那么回直接调用可序列化对象中的writeExternal方法,如果使用的不是PROTOCOL_VERSION_1协议,那么会先开启Data Block模式,再调用writeExternal方法,调用完毕后再关闭Data Block模式并在该流的最后追加TC_ENDBLOCKDATA标记。
值得一提的是,这个方法有一个切换上下文环境的过程——在检测协议前,首先令curPut和curContext为空,检测并写入数据后,再分别令curContext curPut为oldContext和oldPut,恢复执行之前的环境。
为什么要切换上下文? 再来看看writeSerialData就明白了
这个方法主要向obj对象写入数据信息,比如字段值和相关引用等,写入的时候会从顶级父类从上至下递归执行
详细过程:
首先ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
跟进去看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ClassDataSlot[] getClassDataLayout() throws InvalidClassException { if (dataLayout == null ) { dataLayout = getClassDataLayout0(); } return dataLayout; }
翻译注释,该方法返回代表该类描述符所描述的序列化对象的数据布局(包括父类数据)的ClassDataSlot实例阵列。
ClassDataSlots按继承顺序排列,那些包含 “更高 “的父类的实例出现在前面。 最后的ClassDataSlot包含对这个描述符的引用。
也就是说,如果该对象拥有父类,slots里按顺序存放的先是父类后是子类。
也就是说,slots里面存放的是继承结构,用来后续遍历。
接下来开始对slots遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 private void writeSerialData (Object obj, ObjectStreamClass desc) throws IOException ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout(); for (int i = 0 ; i < slots.length; i++) { ObjectStreamClass slotDesc = slots[i].desc; if (slotDesc.hasWriteObjectMethod()) { PutFieldImpl oldPut = curPut; curPut = null ; SerialCallbackContext oldContext = curContext; if (extendedDebugInfo) { debugInfoStack.push( "custom writeObject data (class \"" + slotDesc.getName() + "\")" ); } try { curContext = new SerialCallbackContext(obj, slotDesc); bout.setBlockDataMode(true ); slotDesc.invokeWriteObject(obj, this ); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); } finally { curContext.setUsed(); curContext = oldContext; if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; } else { defaultWriteFields(obj, slotDesc); } } }
首先,判断可序列化对象是否重写了writeObject方法,如果重写了该方法,则先开启Data Block模式,去调用writeObject方法,调用结束后再关闭Data Block模式,并且在最后追加TC_ENDBLOCKDATA标记(表示数据块写入终止),如果没有重写该方法,则调用defaultWriteFields方法写入当前对象中的所有字段的值,跟进defaultWriteFields方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private void defaultWriteFields (Object obj, ObjectStreamClass desc) throws IOException Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException(); } desc.checkDefaultSerialize(); int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte [primDataSize]; } desc.getPrimFieldValues(obj, primVals); bout.write(primVals, 0 , primDataSize, false ); ObjectStreamField[] fields = desc.getFields(false ); Object[] objVals = new Object[desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; desc.getObjFieldValues(obj, objVals); for (int i = 0 ; i < objVals.length; i++) { writeObject0(objVals[i], fields[numPrimFields + i].isUnshared()); } }
翻译注释:
抓取并写入给定对象的可序列化字段的值到流。 给定的类描述符指定要写哪些字段值,以及它们应该以何种顺序被写入。
也就是说,defaultWriteFields方法负责读取 obj 对象中的字段数据,并且将字段数据写入到字节流中。
首先,desc.checkDefaultSerialize();用来判断该类对象是否是一个可序列化的类。
检查完毕后,分两步:
基础类型
获取该对象中所有基础类型字段的值:
1 desc.getPrimFieldValues(obj, primVals);
跟进去:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void getPrimFieldValues (Object obj, byte [] buf) if (obj == null ) { throw new NullPointerException(); } for (int i = 0 ; i < numPrimFields; i++) { long key = readKeys[i]; int off = offsets[i]; switch (typeCodes[i]) { case 'Z' : Bits.putBoolean(buf, off, unsafe.getBoolean(obj, key)); break ; case 'B' : buf[off] = unsafe.getByte(obj, key); break ; case 'C' : Bits.putChar(buf, off, unsafe.getChar(obj, key)); break ; case 'S' : Bits.putShort(buf, off, unsafe.getShort(obj, key)); break ; case 'I' : Bits.putInt(buf, off, unsafe.getInt(obj, key)); break ; case 'F' : Bits.putFloat(buf, off, unsafe.getFloat(obj, key)); break ; case 'J' : Bits.putLong(buf, off, unsafe.getLong(obj, key)); break ; case 'D' : Bits.putDouble(buf, off, unsafe.getDouble(obj, key)); break ; default : throw new InternalError(); } } }
这里面的8个case分别对应8个基本类型首字母:int-long-float-double-short-char-byte-boolean
获得这些基础类型字段的值后,bout会将他们写入到字节流。
对象类型
到这里说明该field是这部分总体来说就是三步:
获取所有序列化的字段
根据desc,获取所有序列化字段的值
递归完成序列化
总结: defaultWriteFields 原生类型直接序列化,而非原生类型则需要递归调用 writeObject0 来对字段序列化。
到这里,整个序列化流程就结束了。
两个特殊点 被transient修饰的成员属性具有”不会序列化“的语义,序列化的时候会忽略;
被static修饰的成员属性隶属于类而非对象,所以它在序列化的时候同样会被忽略。
补充知识:ObjectStreamClass & ObjectStreamField 我们在刚才分析序列化流程中:
出现了desc这个类描述符。它是属于ObjectStreamClass的类对象。
并且很多次出现了解析Field字段时候,出现了ObjectStreamField这个类。
翻阅资料:
ObjectStreamField 按官方的说法是是字段的序列化描述符,本质是对 Field 字段的包装,包括字段名、字段值等 。可以通过 ObjectStreamClass#getFields 获取所有需要序列化的字段信息。ObjectStreamClass 按官方的说法是类的序列化描述符 ,本质是对 Class 类的包装 ,提取了序列化时类的一些信息,包括字段的描述信息和 serialVersionUID。可以使用 lookup 方法找到/创建在此 Java VM 中加载的具体类的 ObjectStreamClass 。
这里其实我的理解是desc就是类的模板,
ObjectStreamField 依据难度先梳理一下ObjectStreamField这个类。
ObjectStreamField类的实例描述了序列化的对象中成员属性的元数据信息 ,上边的这个方法用于判断当前描述的成员属性是一个基础类型的数据还是一个对象类型的数据,若当前描述的成员属性是基础类型这个函数返回true,反之返回false。该成员函数判断数据类型的方式是使用的签名中的类型代码来判断,前文多次提到类型代码的概念,目前可以知道对象类型的数据只有两种类型代码——数组array【[】和对象object【L】。
成员属性 1 2 3 4 5 6 7 8 9 10 11 12 private final String name; private final String signature; private final Class<?> type; private final boolean unshared; private final Field field; private int offset = 0 ;
这里梳理一下:类型,类型代码,类型签名
类型:类对象的型号,Java的成员属性的类型一般对应的Java数据类型为Class<?>;
类型代码:类型代码的数据也是用于JVM判断成员属性数据类型的一种方式,但类型代码的Java数据类型是char ,比如‘L’ ,它一般通过一个字符 来\ 判断**
类型签名:类型签名的Java数据类型是一个String类型 ,比如:‘Ljava/lang/String;’,它和类型代码一样可以用于JVM判断成员属性的数据类型,但是不仅仅如此,JVM在处理类型签名的时候,针对成员属性、成员函数、类本身都可以使用统一的方式来区分,在JVM里面类型签名相当于类型的唯一标识,它的使用 范围比类型代码更加广阔;
构造函数 1 2 3 4 5 6 7 8 9 10 11 12 13 public ObjectStreamField (String name, Class<?> type) this (name, type, false ); } public ObjectStreamField (String name, Class<?> type, boolean unshared) if (name == null ) { throw new NullPointerException(); } this .name = name; this .type = type; this .unshared = unshared; signature = getClassSignature(type).intern(); field = null ; }
可以看到这里第一个构造函数调用了第二个构造函数,并且给unshared属性赋值为false。
注意,这里的构造函数仅仅初始化字段属性,并没有给字段赋值,仅仅是初始化了字段的名称、类型
ObjectStreamClass 这个类主要用来提取序列化过程中某个对象所属类的元数据信息 ,对象所属类包含的元数据信息比起它的成员属性包含的元数据信息要复杂许多。
成员属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private Class<?> cl; private String name; private volatile Long suid; private boolean isProxy; private boolean isEnum; private boolean serializable; private boolean externalizable; private Constructor<?> cons; private Method writeObjectMethod; private Method readObjectMethod; private Method readObjectNoDataMethod; private Method writeReplaceMethod; private Method readResolveMethod; private boolean hasWriteObjectData; private ObjectStreamClass localDesc; private ObjectStreamClass superDesc; private ObjectStreamField[] fields;
再提一下lookup方法:
1 2 3 4 5 6 7 8 public static ObjectStreamClass lookup (Class<?> cl) return lookup(cl, false ); } public static ObjectStreamClass lookupAny (Class<?> cl) return lookup(cl, true ); }
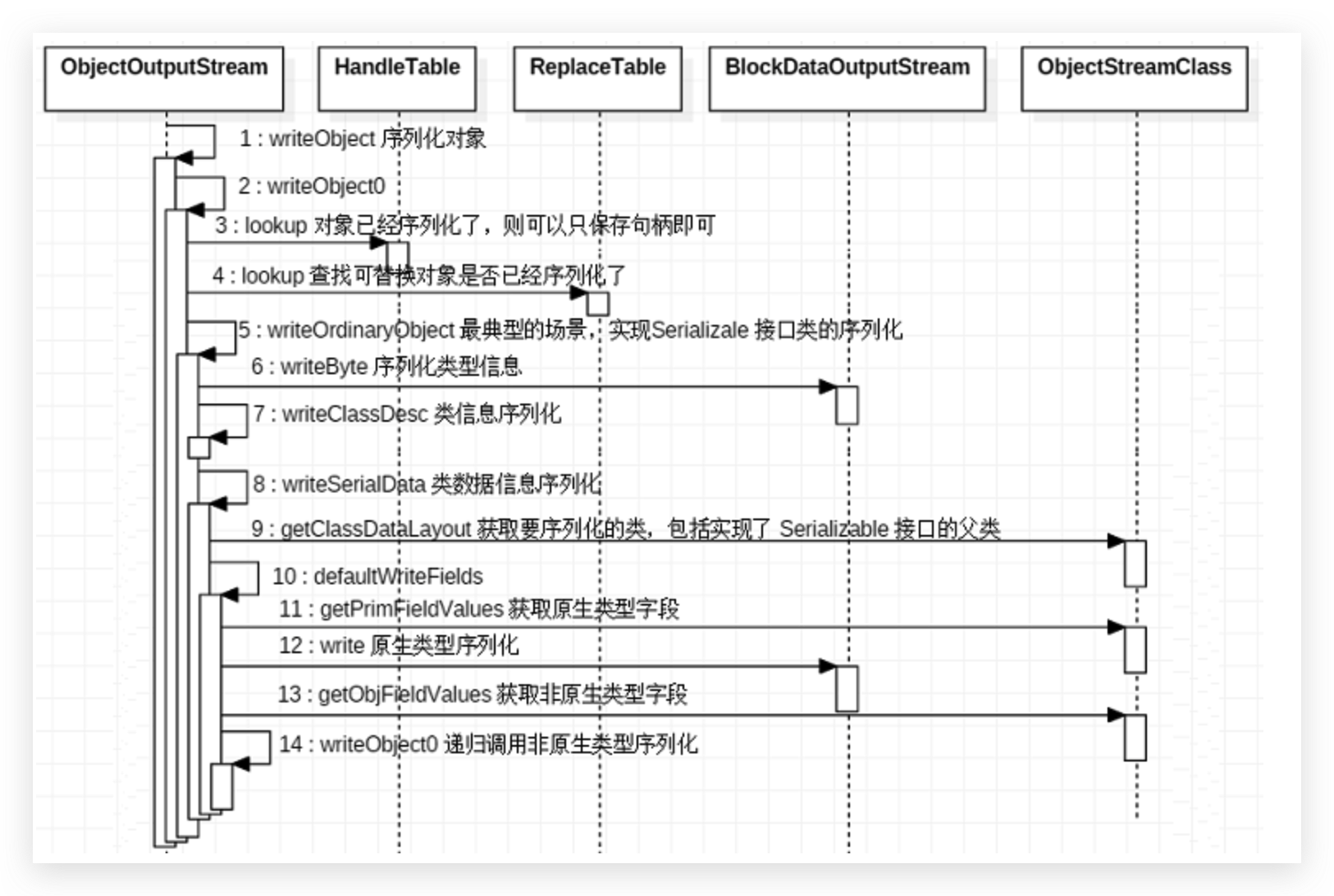
总结 借用binarylei 师傅的图:
每一个序列化结果中,都先包含一段类描述信息,然后才是对象的信息。
注意:
一个类对象如果想序列化成功,要求所有属性实现Serializable接口
transient和static属性不参于序列化
序列化具有继承性,如果一个类实现了序列化,那么他的子类可以参与序列化