序言
江山留胜迹,我辈复登临。
兜兜转转好几圈,发现还是用soot的人多。借此机会,再跟一遍tutorials,写点我自己的理解。
同步项目:MySootScript
SSA
SSA 是static single assignment 的缩写,也就是静态单赋值形式。 顾名思义,就是每个变量只赋值一次。
soot配置选项
1 | Options.v().set_output_format(Options.output_format_jimple);//输出的形式 |
soot的基本数据结构
soot有一个很复杂的层次结构,比如Scene,SootClass,SootClass,SootMethod,Body,Local,Trap,Unit;
Scene:
表示整个分析所发生的环境。
通过Scene可以设置提供给soot分析的所有的应用类、包含main方法的类和有关过程间分析的访问信息。
SootClass:
表示装入到soot中或者由soot创建的单个类。
在Scene中的各个类都是由SootClass类的实例表示的。
一个SootClass包含一个Java类所有相关的信息,例如这个类的类名、修饰符、父类、SootField、SootMethod链等。
SootField:
表示类的属性,也可以叫做域。
SootMethod:
表示一个类中的单个方法。
Body:
Body接口用来表示方法的实现。
在soot中,一个Body隶属于一个SootMethod,即soot用一个Body为一个方法存储代码。
分析应用可以使用Body访问各种信息,如一组声明的局部变量、方法体内语句、以及方法体内处理的异常。
Chain:
链。
每个Body里面有三个主链,分别是Units链、Locals链、Traps链。
Units:方法体内的语句。
Locals:方法内的局部变量。
Traps:方法内的异常处理。
四种Body:
BafBody、JimpleBody、ShimpleBody、GrimpBody,分别对应四种不同的中间表示法。
JimpleBody用得最多。
4种IR
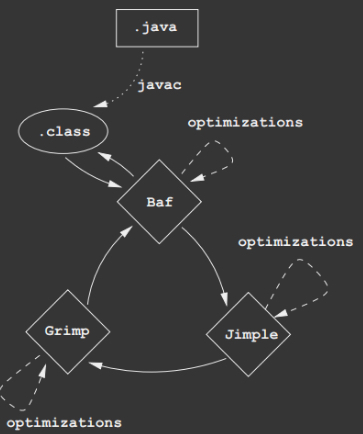
主流IR Jimple
基于栈
java语言的字节码表示本来就是栈的,而象Dalvik 是基于寄存器的,在这点上Jimple基于栈
有类型
每一个参数都定义了Type,并且类型精度没有丢失,比如int $i0
基于三地址分析
三地址解析中会出现很多的中间变量
三地址同时会拆解一些高级特性,被分解成多个单位,包含一些低级操作,支持低端指令一般而言,三地址代码将包含大部分低级操作,即目标机所支持的指令。
此图参考
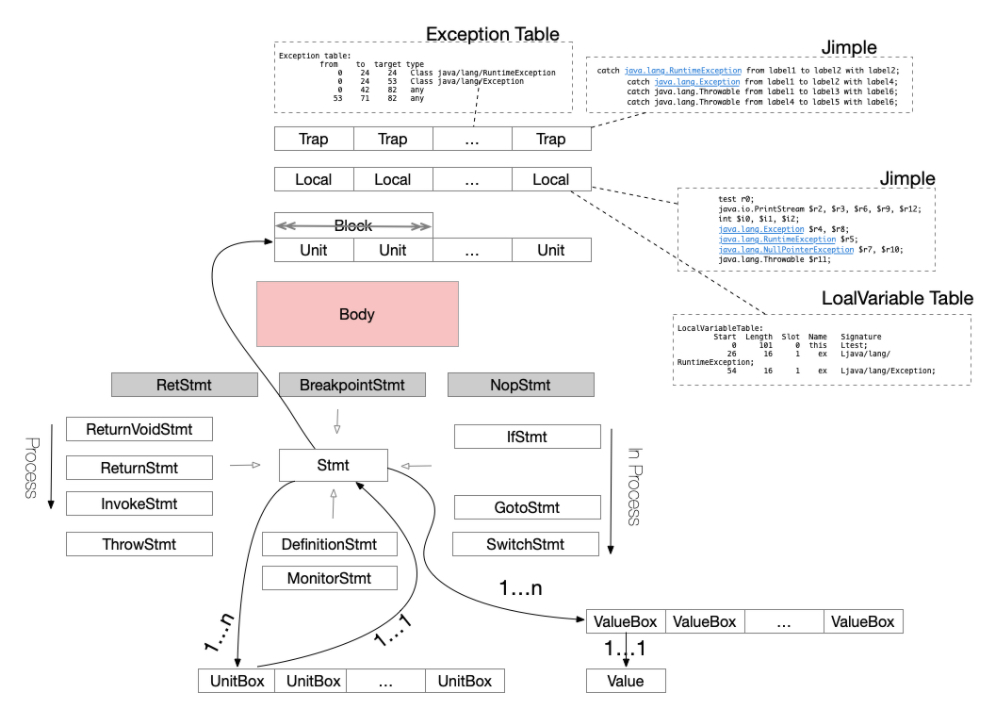
在body中有Units,Values,Traps,接下来细说。
Unit语句在Jimple中就是Stmt。
例如赋值语句:
AssignStmt:x=y+z
##Jimple Stmt类型
核心语句:NopStmt,IdentityStmt,AssignStmt
负责过程内控制流
IfStmt , GotoStmt , SwitchStmt
负责过程间的控制流:
InvokeStmt ,ReturnStmt,ReturnVoidStmt., ThrowStmt
监控语句:MonitorStmt
赋值语句:DefinitionStmt
其它类型:NopStmt, BreakponitStmt
已经不使用的语句RetStmt

Soot为中间代码的翻译建立了一系列的基础设施。
AbstractStmtSwitch
soot.jimple.AbstractJimpleValueSwitch
等等还有很多switch,他们都是针对不同的语句进行了很多情况的分析。
Value&Box
Value:
- Local
- Constant
- Ref
- Expr
这里简单讲一下Expr接口,他又有一系列的实现,例如NewExpr和AddExpr,在下一节会详细介绍。
一般来说,一个Expr可以对若干个Value进行一些操作并且返回另一个Value;
1 | x = y + 2; |
上面这是AssignStmt,他的leftOp是x,rightOp是一个AddExpr(y+2)
AddExpr又包含了值y和2作为操作数,前者是一个局部变量,而后者是一个常量。
在Jimple中,我们强制要求所有的Value最多包含一个表达式。
下面写一些常用的:
Local
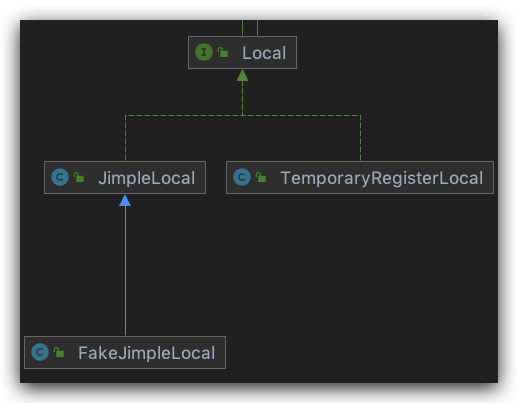
JimpleLocal local变量
TemporaryRegisterLocal $开头的临时变量
Constant
各种常量
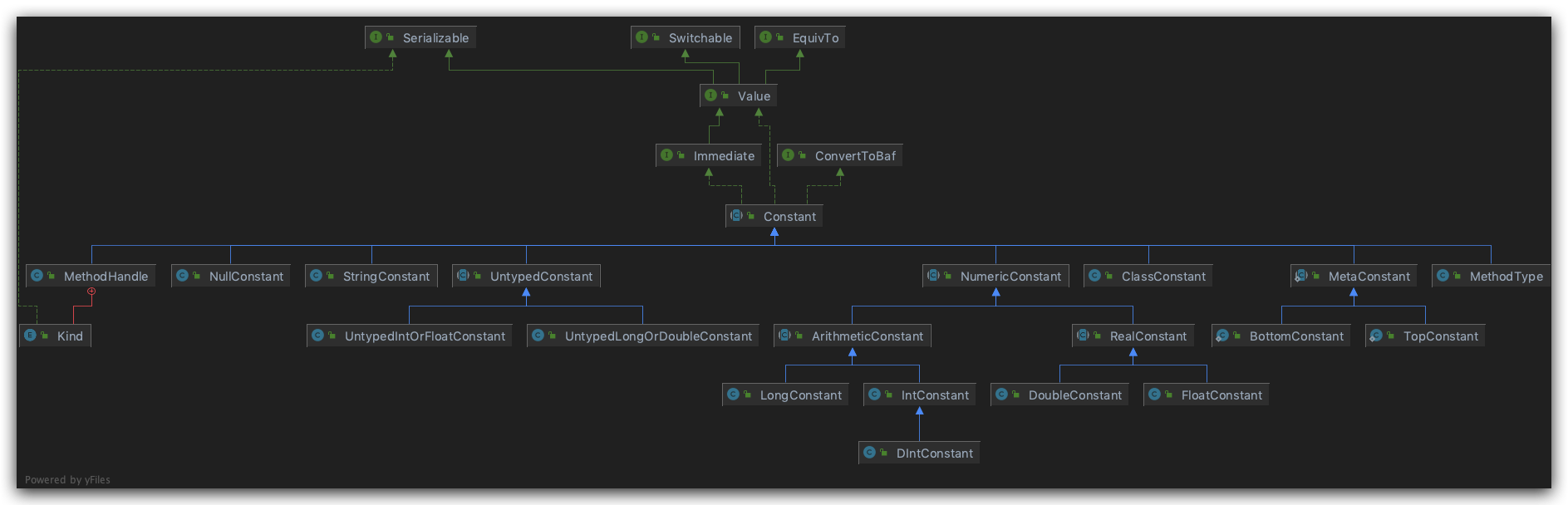
可以说是很完备了
最常用了也就是StringConstant和NumericConstant了。
Ref
引用 相当于指针。RefTypes是以类名为参数。
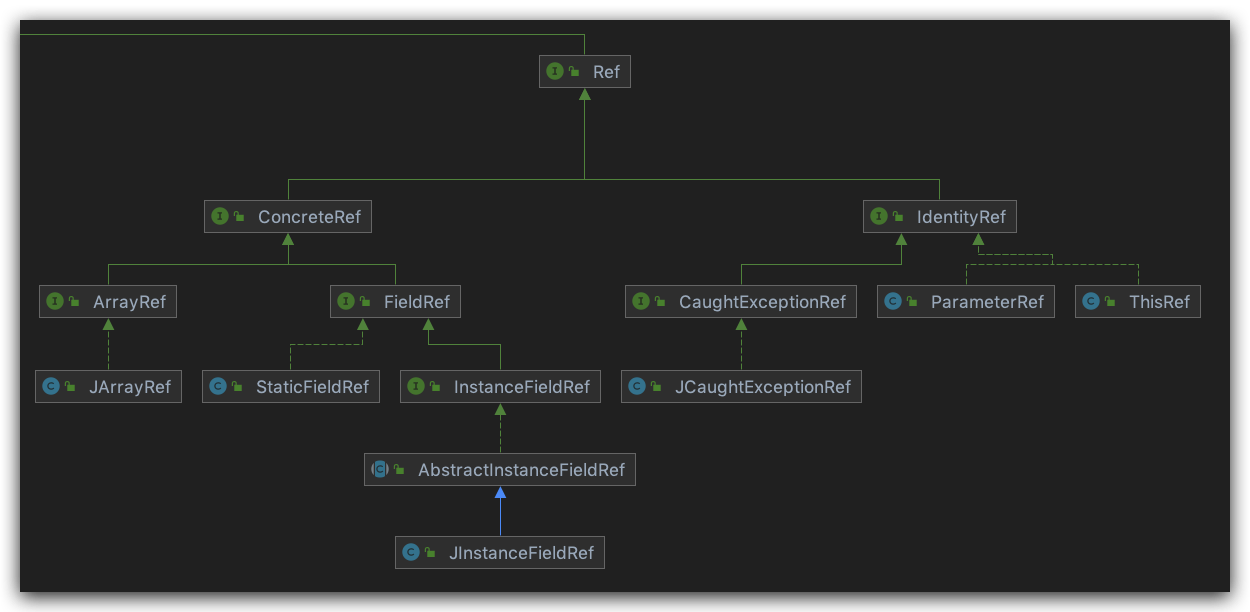
ConcreteRef
- ArrayRef 指向数组
- FieldRef 指向field
- StaticFieldRef 静态field的引用
- InstanceFieldRef 指向的field是一个对象实例
IdentityRef
- CaughtExcrptionRef 指向捕获到的异常的引用
- ParameterRef 函数参数的引用
- ThisRef this的引用
Box
Box是指针!!!!!提供了对Soot对象的间接访问。一个Box提供了一个间接访问soot (Unit,Value)的入口,类似于Java的一个引用,当Unit包含另一个Unit的时候,需要通过Box来访问,Soot 里提供了两种类型的Box, 一个是ValueBox一个是UnitBox。
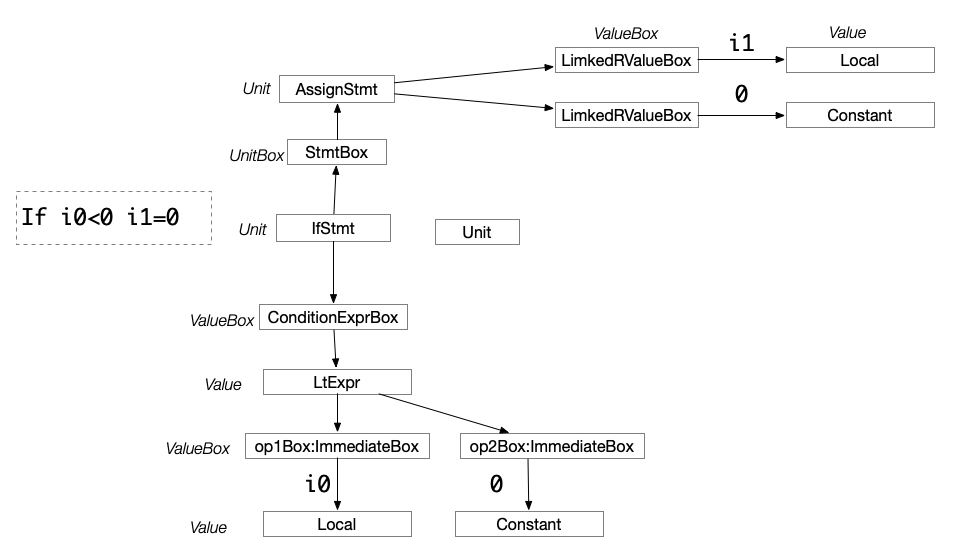
上图可以看出来:
- 一个Unit有多个UnitBox,但是每个UnitBox只能指向一个Unit。GotoStmt 需要知道目标的Unit是什么,所以一个Unit会包含其它的UnitBox,通过 UnitBox获取下一个Unit。
- 一个Value可以对应多个ValueBox,但是一个ValueBox只能对应一个Value,对于一个Unit,可以得到很多个ValueBox,包含着这条语句内部的所用到和所定义的语句。
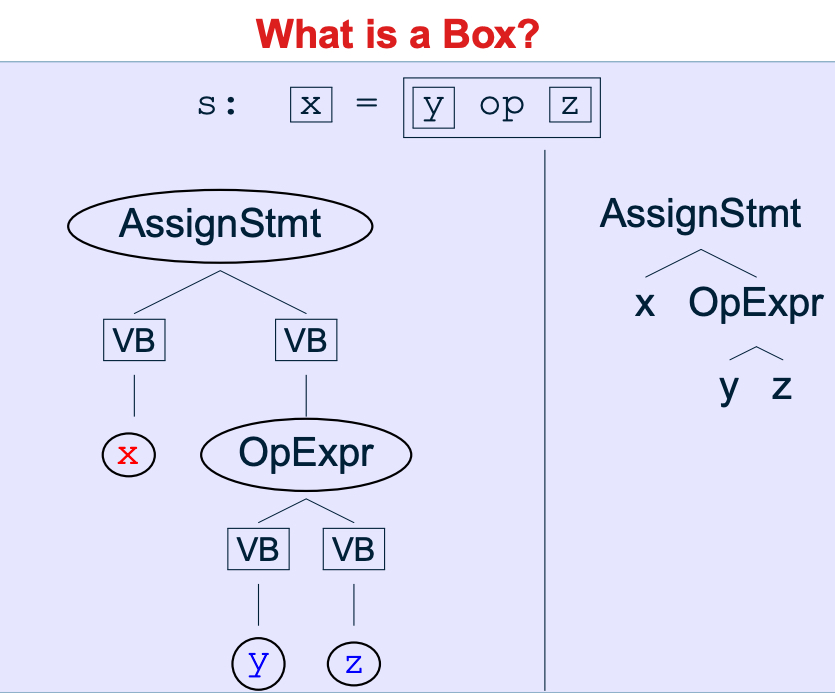
两种Box:
- ValueBox,指向Values
- 对于一条Unit来说,他的ValueBox存储的是在这条语句内部所用到的和所定义的语句。
- UnitBox,指向Units
- 以goto语句为例,UnitBox其实存的就是goto所指的下一跳节点。
- switch语句,则会包含很多boxes
i1=0 等于是一个Stmt, i1是一个Valuebox,里面包含这i0这个local 的value。
多说几句:
DefBox是什么?
List defBoxes = ut.getDefBoxes();

举例常量叠加:
1 | int a = 1; |
由于a,b的值都是常量,需要叠加一下,当然这部分soot内部已经实现了:
对于int c = a + b来说,这句话是一个赋值语句,也就是AssignStmt,在这个赋值语句中,左边是Local,右边是AddExpr,他们都是Value类型。
下面算法的逻辑:
- 对于这个AssignStmt来说,需要首先获取他的Boxes,这些Boxes里面包含了Value的指针。
- 遍历Boxes,cast为ValueBox,然后获取他的Value,如果是AddExpr的话,那就是我们想优化的。
- 对于AddExpr来说,获取他的左值和右值,也就是两个value。
- 如果都是常量IntConstant的话,那么就把他们的value加在一起。
- 重新给AssignStmt的box赋值,让他指向sum和的常量。

对于Unit语句类型来说,必须包含的方法有:
1 | public List getUseBoxes(); |
这些方法会返回在这条Unit语句内部Use的,Define的,或者两者都看。会以List of ValueBox的形式返回。
对于getUseBoxes()方法,将返回所有使用的值;当然包括各种Expr表达式及其组成部分。
1 | public List getUnitBoxes(); |
上面这个方法会返回一个List (UnitBox),包含所有被这个Unit所指向的其他Unit。
1 | public List getBoxesPointingToThis(); |
上面这个方法会返回一个List(UnitBox),包含那些指向这个Unit的Unit语句。
1 | public boolean fallsThrough(); |
处理在某条语句之后的执行流有关。
第一个方法:如果执行可以顺利流到紧挨着的下一条语句,就会返回True;
第二个方法:如果执行可以继续流下去,但是并不会流到紧挨着的下一条语句,返回True。
1 | public void redirectJumpsToThisTo(Unit newLocation); |
上面这个方法会用getBoxesPointingToThis方法去改变所有曾经指向这个Unit的跳转,让他们都指向这个新的newLocation。
总结:
我们能够确定跳转到这个Unit的其他Unit(调用getBoxesPointingToThis()),也可以找到跳到的其他Unit(调用getUnitBoxes())。
1 | public List<ValueBox> getUseBoxes();//返回Unit中使用的Value的引用 |
Stmt和Expr的区别
statement没有返回值
expression有返回值
Stmt的基本实现都在soot.jimple.internal中,我们把目光聚集到Jimple这种IR。关系图如下:
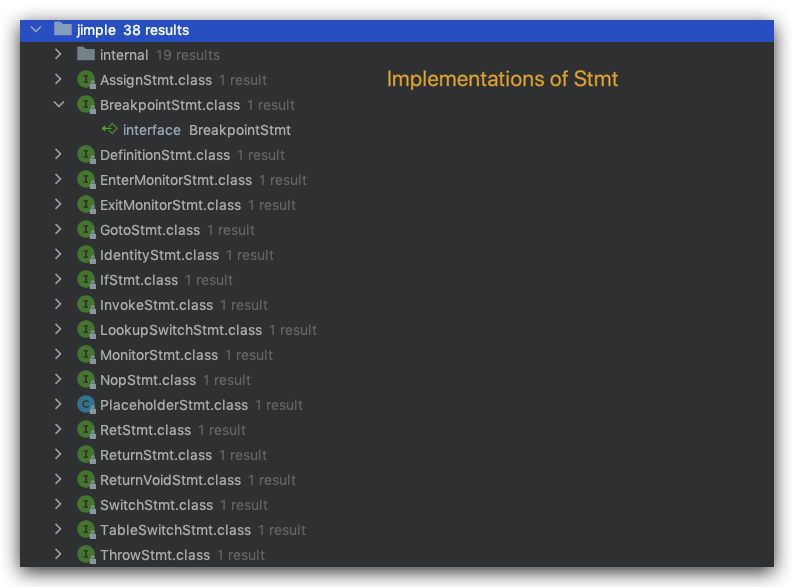
正如上图所示,soot.jimple包里面,internal包内部存放的是实现了Stmt的抽象类,没有在internal包内存放的是继承了Stmt接口的其余接口。
AbstractStmt
在internal包内,最先实现Stmt接口的是AbstractStmt接口:
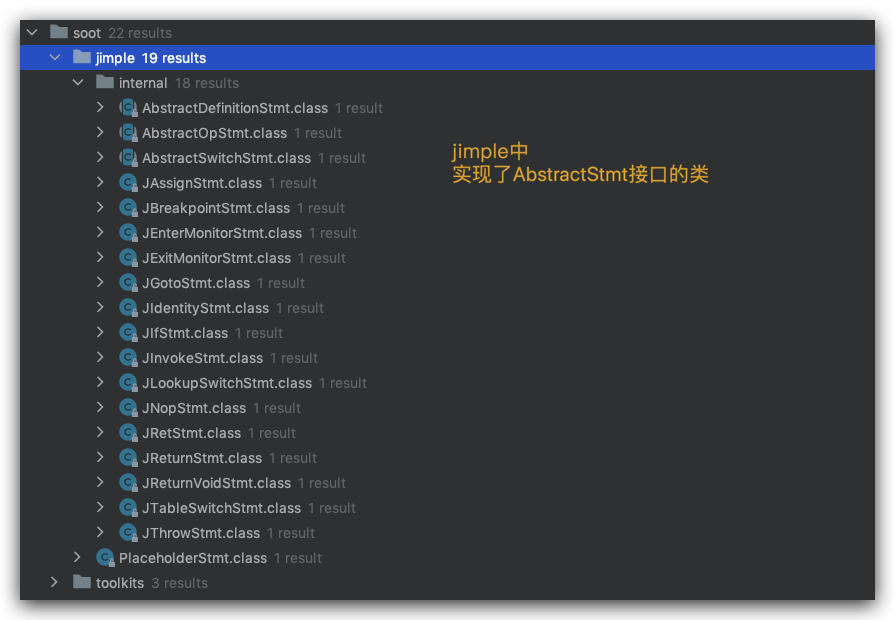
读到这里,我相信你应该有点感觉了,soot架构里面的抽象类应该都有对应的实现。
这也就是为什么,剩下的三个抽象类肯定还有具体的实现。
AbstractDefinitionStmt
表示一个赋值语句
我们先看AbstractDefinitionStmt抽象类的实现
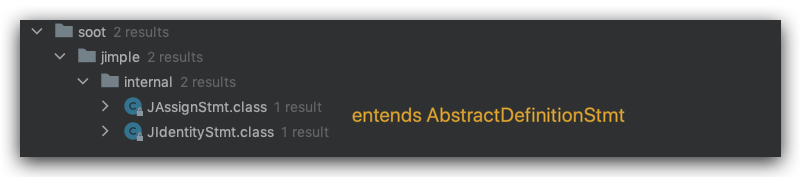
JAssignStmt
一个正常的复制语句
比如说可以给一个堆栈变量$stack5赋值
1 | $stack5 = newarray (java.lang.Object)[0] |
$变量其实就是模拟了JVM中局部变量表里面的堆栈变量,本质上也是一种Local
JIdentityStmt
通常指的是对变量赋值,这个变量既可以是显示的也可以是隐式的
函数传参,程序会帮你把从参数传入的变量,赋值给一个临时变量,给函数内部调用
1 | r1 := 0: java.lang.String |
this变量
1 | r0 := : com.spring.Controller |
两者区别!!!
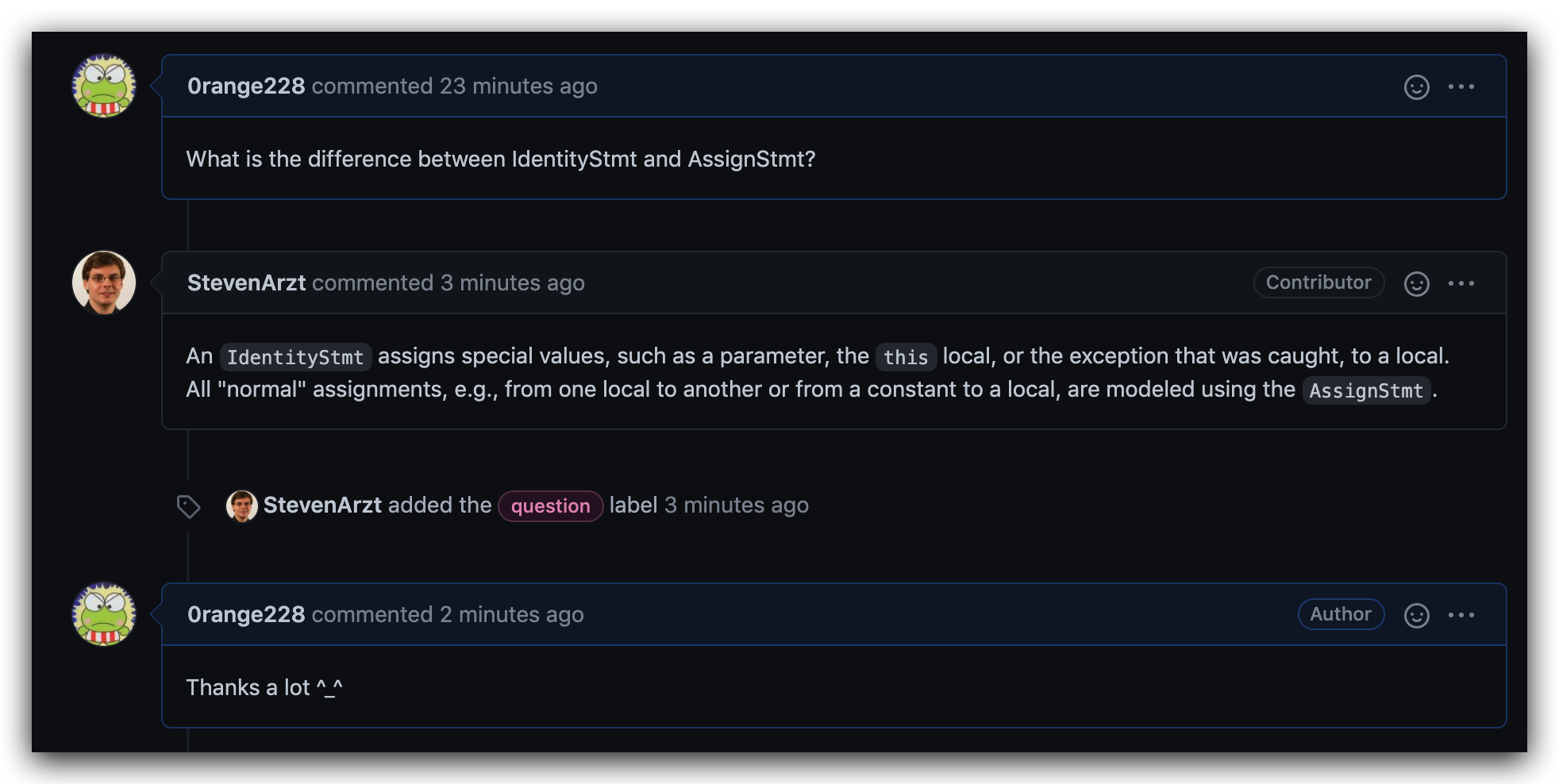
可以理解为:
一个IdentityStmt将特殊值,如参数、this或被捕获的异常,分配给一个Local。
所有 “正常 “的赋值,例如从一个Local到另一个Local,或者从一个Constant到一个Local,都是用AssignStmt表示的。
不同的IdentityStmts的共同点是它们分配的值都是 “神奇地从天而降”。在方法入口处,这些是参数和 “this”,而在异常处理程序中,这些是抛出的异常。换句话说,在处理程序开始的地方,在方法的主体里有一个带有异常引用的IdentityStmt是完全可以的,也是人们所期待的。Soot的唯一假设是,如果一个语句是Trap的目标,即处理程序的开始,那么该处理程序中的第一个语句应该是一个带有适当异常引用的IdentityStmt。
AbstractSwitchStmt
switch语句主要由于JVM对于不同的Switch语句,会生成不同的操作指令,从而也就有了两种Switch语句
JLookupSwitchStmt lookup类型的switch
JTableSwitchStmt table类型的switch
AbstractOpStmt
四个实现类
| 类 | 表示 |
|---|---|
| JEnterMonitorStmt | 线程进入 |
| JExitMonitorStmt | 线程退出 |
| JReturnStmt | return语句 |
| JThrowStmt | throw语句 |
其他Stmt 直接写上
| Stmt | 含义 |
|---|---|
| JInvokeStmt | 调用方法的语句 |
| JBreakpointStmt | break语句 |
| JGotoStmt | go to语句 |
| JIfStmt | if 语句 |
| JNopStmt | nop跳转 |
| JRetStmt | jsr 基本不用了 |
| JReturnStmt | return语句 |
| JReturnVoidStmt | return void 语句 |
AbstractInvokeExpr
表示调用的表达式
之前也提到过,invoke一共有五种:
| 类型 | soot | 具体用途 |
|---|---|---|
| invokestatic | JStaticInvokeExpr | 调用static静态方法 |
| invokevirtual | JVirtualInvokeExpr | 调用虚方法、final方法 |
| invokeinterface | JInterfaceInvokeExpr | 调用接口方法,在运行时搜索实现了这个方法的对象,进行合适的调用 |
| invokespecial | JSpecialInvokeExpr | 调用实例方法,init构造方法、private、父类方法 |
| invokedynamic | JDynamicInvokeExpr | 动态解析出需要调用的方法,然后执行 invoke lambda |
这五种被soot指派了两个抽象类来实现:
调用方法 静态static + 动态dynamic
JStaticInvokeExpr
JDynamicInvokeExpr
AbstractInstanceInvokeExpr
调用一个变量调用自身的方法
- JVirtualInvokeExpr
- JInterfaceInvokeExpr
- JSpecialInvokeExpr
这部分soot还有一种划分方式,
InvokeExpr
InstanceInvokeExpr
- JVirtualInvokeExpr
- JInterfaceInvokeExpr
- JSpecialInvokeExpr
StaticInvokeExpr
- JStaticInvokeExpr
DynamicInvokeExpr
- JDynamicInvokeExpr
AbstractBinopExpr
一堆数学操作,加减乘除、逻辑与或非、比较、位运算
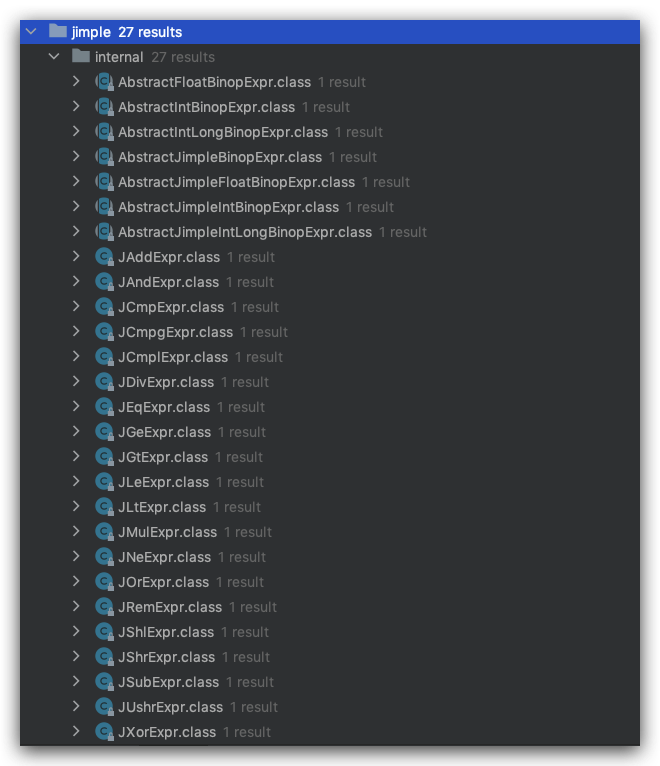
其他Expr 直接写上
| Expr | 含义 |
|---|---|
| JCastExpr | cast 强制类型转换 |
| JInstanceOfExpr | instanceof |
| JNewMultiArrayExpr | 多维数组 |
| JNewExpr | new |
| JNewArrayExpr | 创建new array |
| JLengthExpr | 数组长度 |
| JNegExpr | 否定一个int变量 |
处理阶段Pack/Transformer
程序内分析:
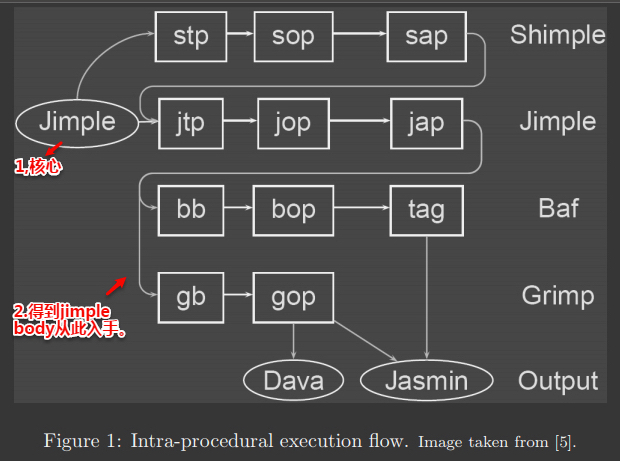
上面这张图是程序内分析大致框架图,入口点是Jimple,用户可以在转化阶段加入一些分析相关的信息。这个可以在jtp(Jimple Transformation pack)阶段来实现。
代码:
1 | PackManager.v().getPack("jtp").add(new Transform("jtp.myTransform", new BodyTransformer(){ |
上述代码就是在jtp pack中插入小步骤myTransform,但soot的执行流执行完自定义的myTransform后,将继续沿着执行流执行,自定义的小步骤就像soot的一个插件,并不影响其他的执行流顺序。
程序间分析:
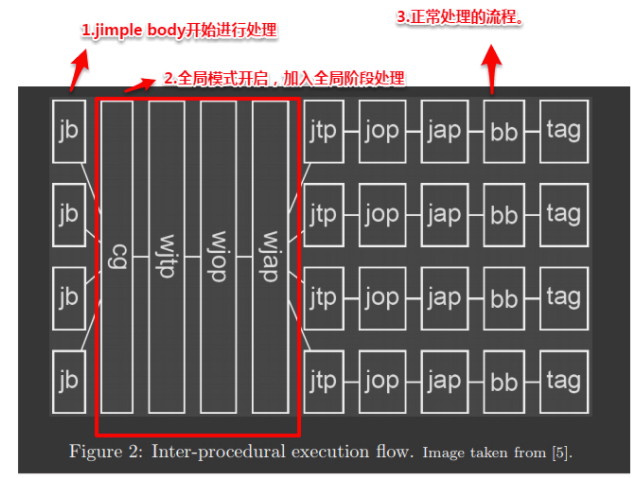
第二张图是程序间程序分析
代码:
1 | PackManager.v().getPack("wjtp").add( |
上述代码就是在wjtp pack中插入一个小步骤myTransform。 但soot的执行流执行完自定义的myTransform后,将继续沿着执行流执行,自定义的小步骤就像soot的一个插件,并不影响其他的执行流顺序。
这里总结一下各个阶段的命名规则:
第一个字母表示中间代码种类:
- j=Jimple
- s=Shimple
- b=Baf
- g=Grimp
第二个字母表示该阶段做的事情:
- b=body 方法体创建阶段
- t=transform 用户自定的创建阶段
- o=optimizations 优化阶段
- a=annotion 属性生成阶段
最后的P:
- p=pack 处理阶段
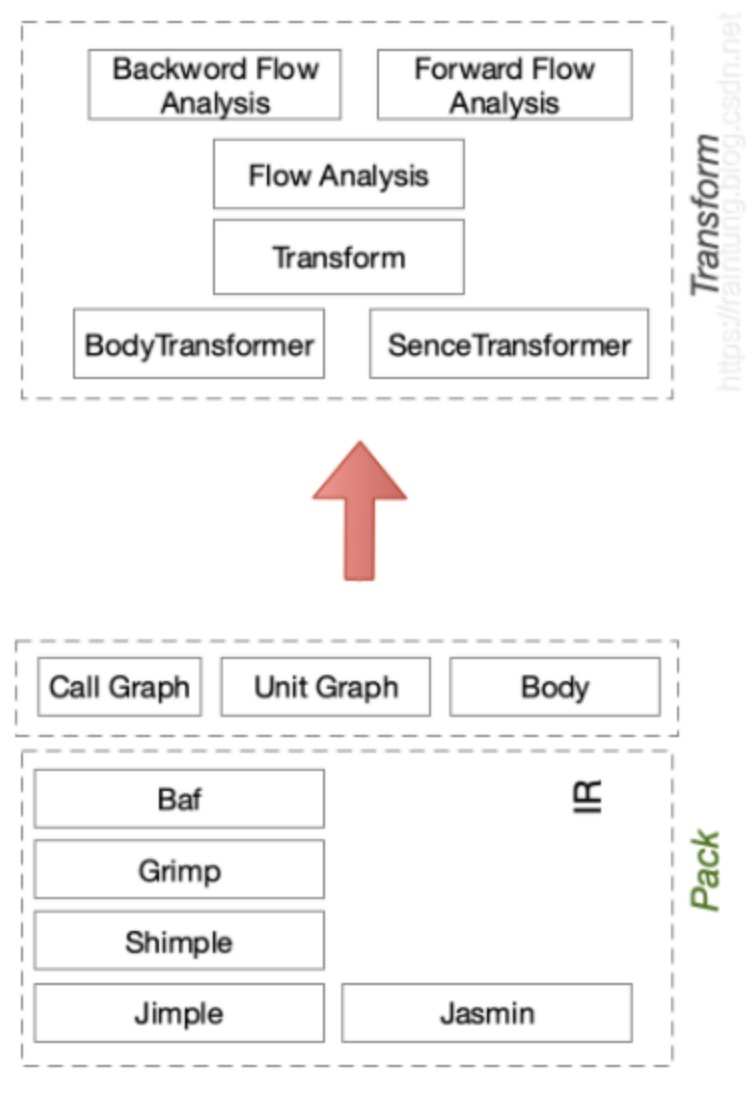
核心阶段与小阶段
在Soot的核心阶段分为PP->CG->TP->OP->AP,Soot支持多IR分析,但在核心过程中只支持Jimple, Shimple, 在Pack中可以插入自定义的Transform,这样就可以在每一个分析阶段加入自己的分析步骤,从而实现自定义分析的能力。
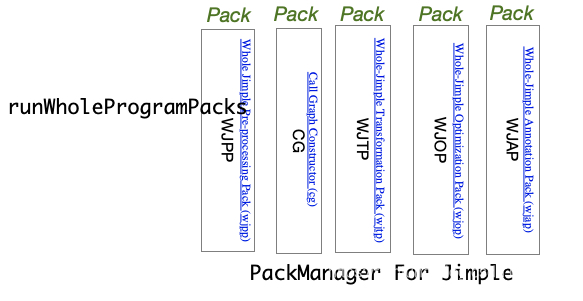
但是一开始jb都是必须要做的,生成jimplebody,下图中,jb阶段就是核心阶段,下面罗列的就是小阶段:

具体每个小阶段是干嘛的,可以看这里
PP
Pre-processing Pack 是第一个分析的Pack,该Pack允许你自定义一些自己的transform在构建call graph之前。
CG
CG Call Graph,调用图,调用图是静态层序分析的关键,方法调用图包含着整个函数调用的关系图。
body packs
Body Packs 基于Body 的Packs分析,对不同的IR有不同的Packs。
和前面的核心Packs不同的是,这里只是基于Body进行分析,每个Packs依然可以自己定义Transform,区别是使用不同的Transformer,在Body packs里使用的是BodyTransformer。
1 | protected abstract void internalTransform(Body b, String phaseName, Map<String, String> options); |
internalTransform里面包含了Body 对象
与核心的Pack分析不同的是,当分析到Body的Packs的时候,Soot会启动多线程进行Pack的分析。
在Soot里,每个阶段都又对应的pack来完成。
Pack其实具体来说就是一组变换器(Transformer),每个变换器对应着相应的子阶段。
当Pack被调用时,它按照执行顺序执行每一个Tranformer。
提供拓展机制的是那些允许用户自定义变换的Pack:
- jtp:Jimple-transformation-pack
- stp:Shimple-transformation-pack
在不改变Soot自身的情况下,用户往往可以自定义满足需求的类(变换器),然后将其注入到这些pack中,之后调用soot.Main(),使其进入到Soot的正常流程调度中。
Transformer
Transformer是Soot的变换器,允许用户自定义。
Soot变换器通常是继承两种:
- BodyTransformer:针对单个方法体,过程内,进行变换;
- SceneTransformer:针对整个应用,过程间,进行变换。
这两种方法下,变换器类都必须重构internalTransform方法,在这个方法里对被分析的代码执行某种变换。
你的transformer也可以分开写:
1 | PackManager.v().getPack("jtp").add(new Transform("jtp.myAnalysis", new MyAnalysis())); |
控制流图 CFG
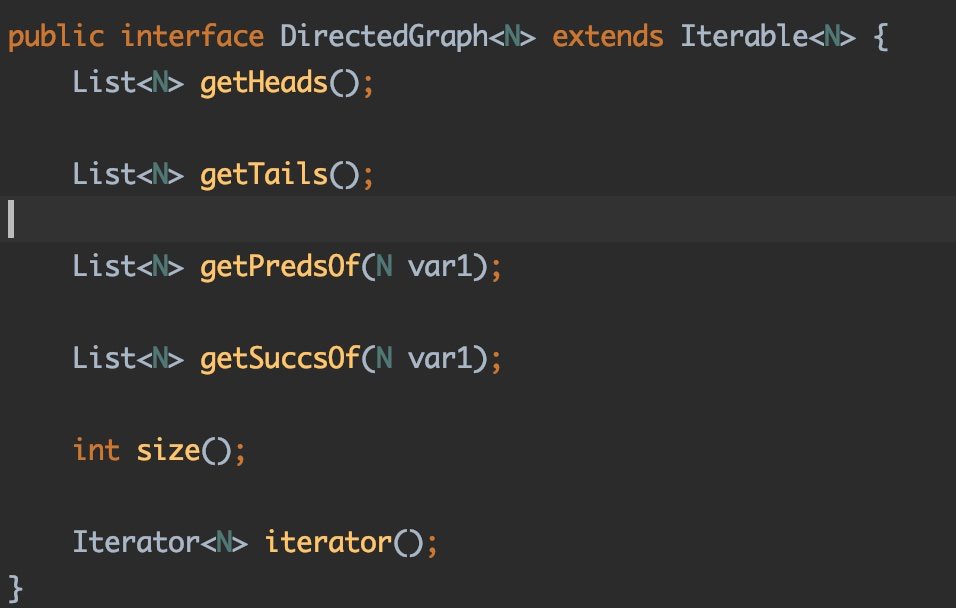
soot有两种类型的控制流图(两个抽象类,均实现DirectedGraph接口):
- UnitGraph
- BlockGraph
区别:
UnitGraph是语句图,结点是Units。
BlockGraph是基本控制流图,结点由基本块BasicBlocks组成。
共同点:
首先这两种类型图的表示是相通的。
该接口中的API们,可以获取到:
- 图的入口节点和出口节点;
- 一个给定节点的前驱结点和后继结点;
- 一个以某种未明确规定的顺序和节点数在图中进行迭代的迭代器。
- 图的大小规模(节点数)
在这些基础上就可以开发对任意DirectedGraph有向图进行处理的方法。
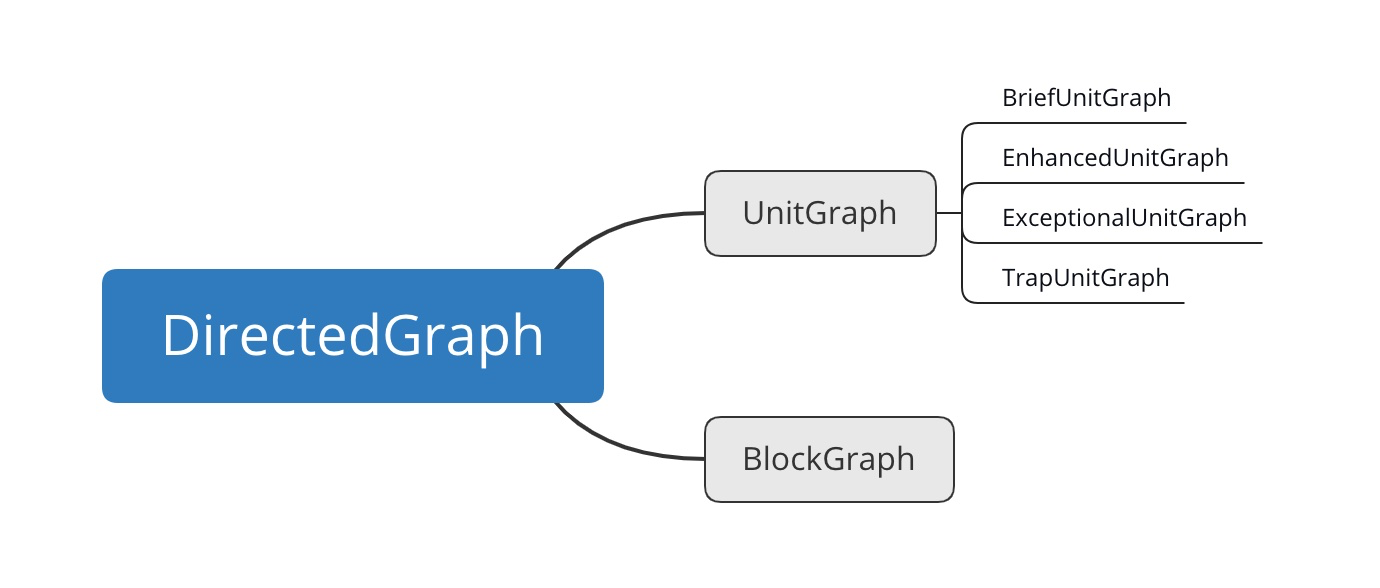
实际上,UnitGraph和BlockGraph都是抽象类,Soot自己也实现很多实例化的子类。
例如CompleteUnitGraph、BriefUnitGraph、CompleteBlockGraph、BriefBlockGraph等。
具体在soot.toolkits.graph有实现说明。
继承实现关系
语句图UnitGraph
巧妙之处:数据的关系与数据的内容进行了分离。
UnitGraph只是将Unit中的关系进行了保存,并不会改动Unit,Body的内容。
soot中UnitGraph是一个抽象程度较高的语句图。
重点说一下UnitGraph:
UnitGraph的优点是简化了控制流图,没有了基本块的概念。
使用它可以简化传统的固定点数据流分析的实现。(fixed point data flow analysis)
但是缺点是由于没有了基本块,那么也就增加了分析时间的开销。
UnitGraph的四个子类
继承UnitGraph的有4种:
- BriefUnitGraph 【用得最多】
- EnhancedUnitGraph
- ExceptionalUnitGraph
- TrapUnitGraph
API:

BriefUnitGraph:
【正常,异常分离】BriefUnitGraph将正常的流程,与异常的处理流程进行了分离。(不相交,在最后才进行汇聚);不包含针对exception的边
ExceptionalUnitGraph:
【融合】将正常流程与异常流程进行了融合,而不再是分离的。包含exception的边
- 包含从throw到catch的边,soot里面叫Trap
- 它还会计算语句中隐含的异常抛出
- 会有一条边从抛出异常那条语句的前驱节点指向异常处理的第一条语句Unit
- 如果包含异常的语句包含一些副作用,那么有副作用的边也会被添加到图里面
TrapUnitGraph:
【相对于ExceptionalUnitGraph】一些很普通的语句也会跳转到异常流程中。(比如nop,goto[?=nop])—->认为try 中包含的所有的语句都有可能触发异常。
- 边是从trap语句连接到trap handler,例如try块
- 对于那些隐藏异常抛出的语句,这类图在他们的前驱节点并不会抛出一条边到handler
- 但是在那些隐藏异常抛出的语句本身会抛出一条语句指向handler
通过以下代码对给定的函数创建CFG:
1 | UnitGraph g = new ExceptionalUnitGraph(body); |
Host & Tag
soot层次如下图:
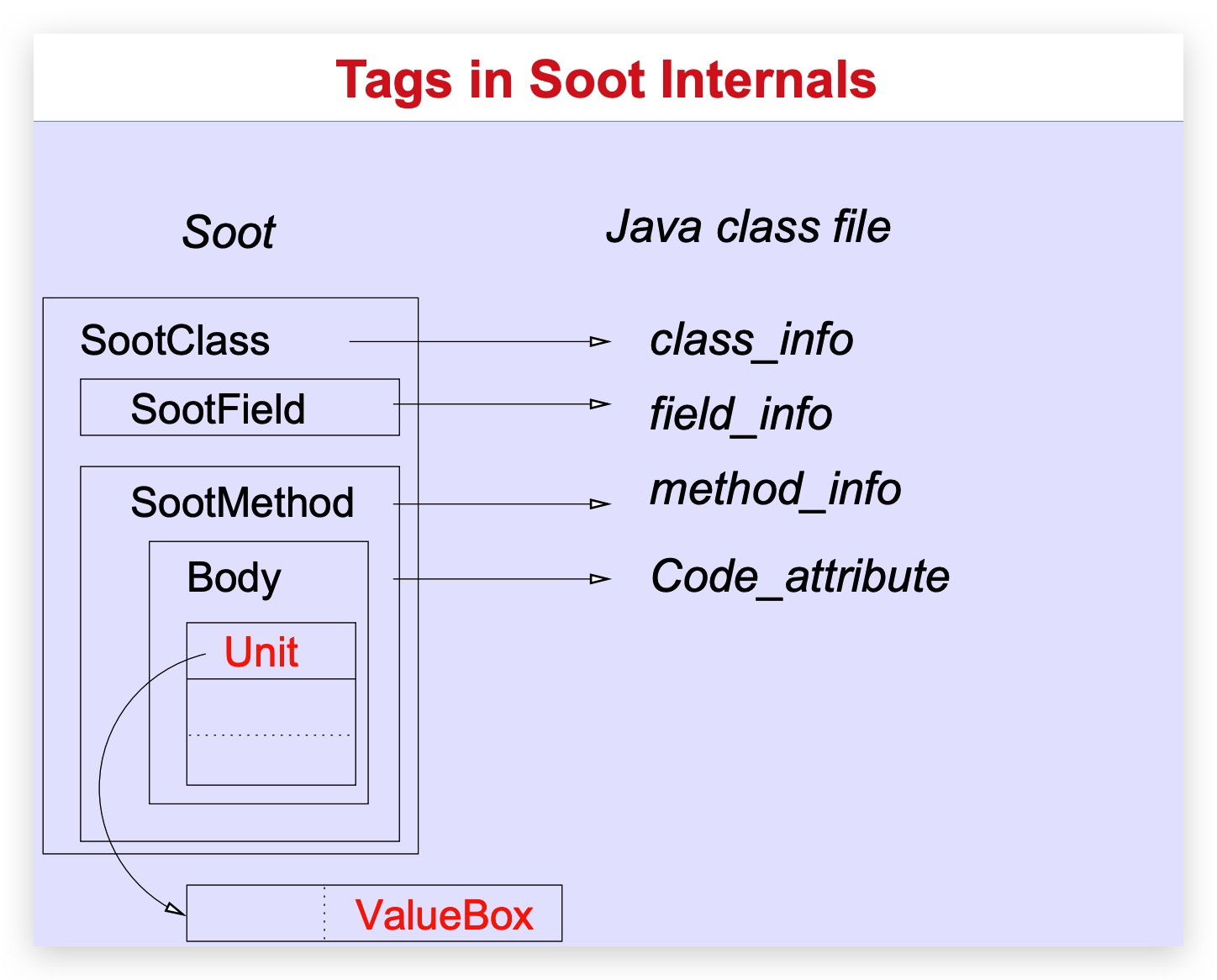

Tag的接口由Host负责。

Call Graph & Point-to
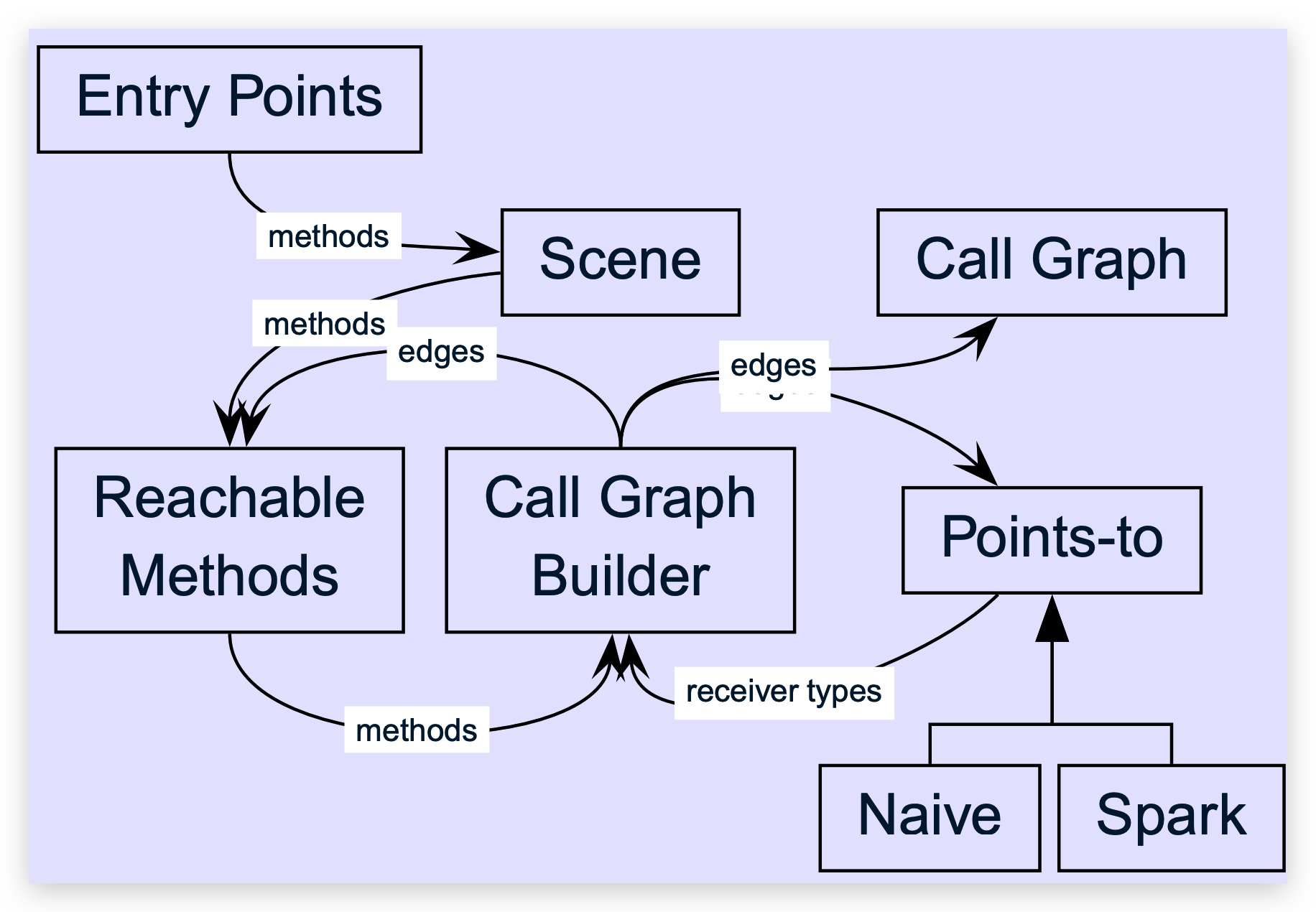
CG & CFG & ICFG
CallGraph & Control Flow Graph & Interprocedural Control-Flow Graph
CG代表的是整个程序中方法之间调用关系的图,图中节点是函数,边代表的是调用关系。
CFG代表的是一个方法内程序执行流的图,图中节点是语句组成的基本块,边代表执行流。
CFG上条件语句节点的后缀会有多个,表示其后可能执行的不同branches。
ICFG就是CG+CFG,可以看作是CG和CFG信息的叠加。ICFG可以看做是给所有方法的CFG加上这些方法之间互相调用的边(CG)所形成的图。调用边(call edge)从调用语句(call site)连到被调方法(callee)的入口。与CG不同的是,ICFG除了调用边,还包含相应的返回边(return edge),从callee的出口连到call site之后执行的下一个语句。
CG Call Graph
调用图,调用图是静态分析的关键,方法调用图包含着整个函数调用的关系图。
edge:
Querying Call Graph


Reachable Methods
记录从entry method开始可以到达的方法们


Transitive Targets

CallGraph结构:
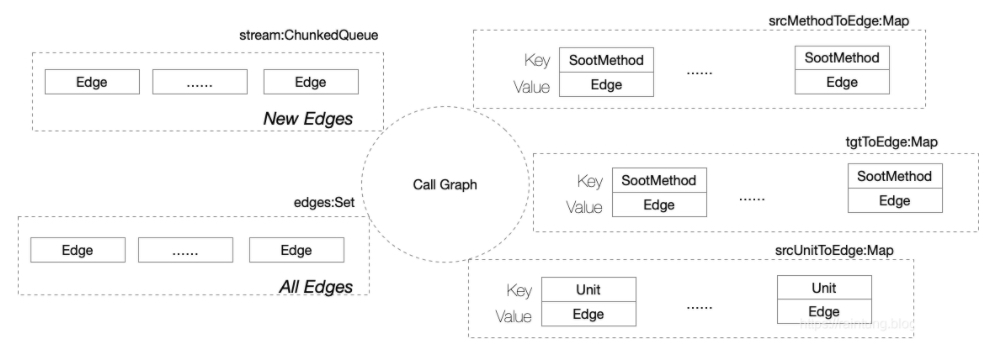
Call Graph对象里包含了所有的Edges的集合,同时也包含了了几个关键Map
- src Map
- target Map
- unit Map
这些Map的Key是SootMethod,Unit而Value是Edge,为了更快的找到SootMethod或者Unit对应的Edge。
CallGraph构建
Call Graph是方法的调用图,要画出方法的调用图是需要起始点的,也就是我们常说的EntryPoint。

在全程序分析的模式下,当一个调用图构建时,我们可以用Scene类里面的getCallGraph方法。
包含3个处理的办法,
CHA SPARK Paddle,
其中默认生成call graph使用的是CHA,CHA生成速度快,但是是最不准确的。
CHA是最简单的分析方式,它是默认程序中所有的路径都是连通的。
1 | CHATransformer.v().transform(); |

这里前提是必须开启全局模式:
1 | Options.v().set_whole_program(true); |
举例:
1 | ... |
这里分析一个简单的程序:
1 | public class CallGraph { |
soot code:
1 | public class Test { |
查看doStuff能调用哪个方法,CHA结果:
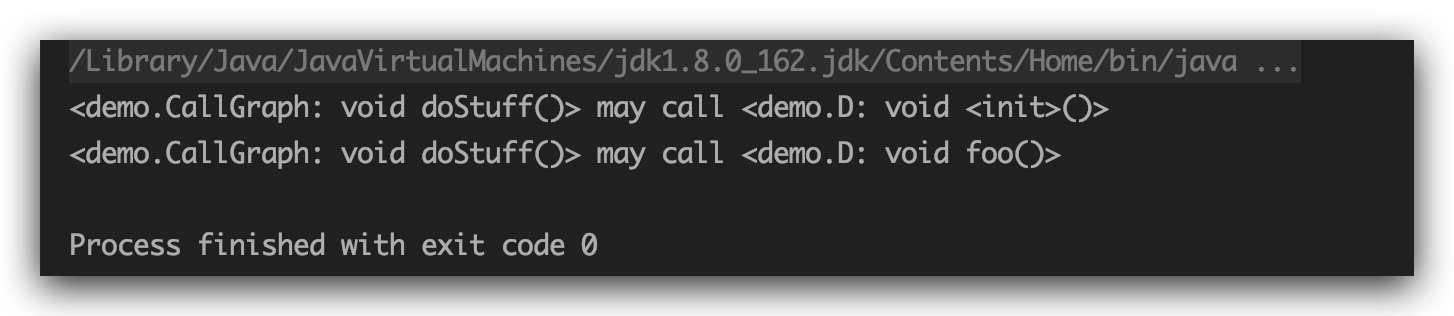
发现并不是绝对的准确的结果
备注:
PackMananger是负责进行阶段处理的,它控制着各种执行的运行,不启动则不会运行相应的阶段。
Spark
Spark分析
Spark针对的是对于Java的指向分析,支持 基于集合的分析,以及 基于等值的分析。
但是,Spark提供的是基于上下文不敏感的子集的点对点分析。
指向分析(points-to)只是SPARK分析的一部分,一系列不同层次,不同方面的分析,可以通过配置options来实现。
1 | HashMap opt = new HashMap(); |
解读:
1 | - verbose. (设定SPARK在分析过程中,打印多种信息【提示信息】) |

SPARK运行结果:

解读:
左边列的数字表明,变量初始化的点。(比如:[4,8] Container intersect? false,中的数字表示在第4行初始化的变量,以及在第8行初始化的变量 )
右边列表示,两个变量的指向的集合中交集是否为空。不空为true,空为false。
【结果分析】可以看出,c1自己与自己是有交集的。c1与c2是没有交集的。(c1, c3也是如此)
Point-to
interface
1 | reachingObjects(Local) 返回指向某个Local变量的指针集合PointsToSet |
例子a
1 | o.m() |
例子b
1 | x.f = 5; |
数据流分析
在soot里面分为过程内数据流分析和过程间数据流分析。
程序可以看成是状态(数据)和状态之间的转移(控制)两部分,因为状态转移的条件都被忽略了,核心分析的部分是状态数据在转移过程中的变化,所以叫做数据流分析。
首先,总体来说:
- 每个语句相当于一个小的加工厂,加工厂加工需要一定的原料(输入 in),并且会产生一定的效果(输出 out)。
- out = in - kll +gen这个公式反映了数据流分析的本质,这让数据在语句中真正流动起来(在数据流分析中)。
- kill和gen是主要依赖于语句本身的。比如说,a = 100这个语句的作用是将a中之前的值抹去(kill),同时放入 100的值(gen)。
- out反映的是语句处理之后造成的后果。
近似分析
对于IfStmt来说,会出现branch分叉,那么对于汇聚点来说,就会存在Locals的不确定态。
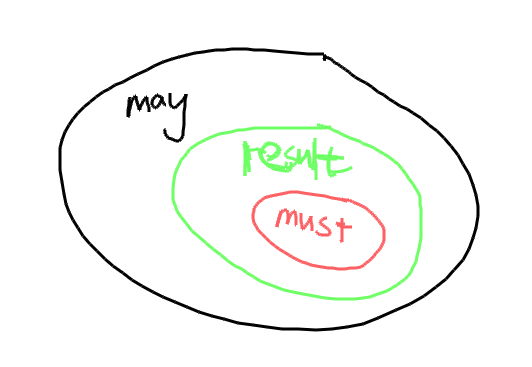
近似的两种级别
must
取交集,分析的结果一定被包含于正确答案之内。
may
取并集,分析的结果包含正确的答案。
举例:
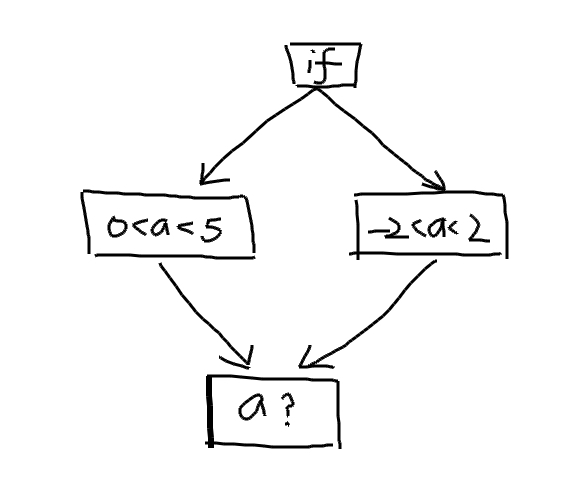
may:-2 < a < 5
must: 0 < a < 2
敏感性
程序分析的精度通常是和敏感性相关的。主要介绍下面几种敏感性:
- 上下文敏感性 context-sensitivity
- 路径敏感性 path-sensitivity
- 流敏感性 flow-sensitivity
谭添老师总结得很好:
通常所说的xxx-sensitive是指静态分析中用于降低误报(false positive)的技术,最常提的xxx正是所说的path, context以及flow。要具体解释这几个概念,首先我们来看看静态分析怎么产生false positive误报,然后我们再来看看如何用这几个技术(或者说概念)消除相应的false positive。
我们做静态分析时,无论是分析源代码还是目标代码,我们分析的对象(方法、语句、变量)都只有一份:同一个方法我们只会写一个方法体(方法体里的语句也就只有一份),同一个变量我们只会声明一次。然而动态运行程序的时候:
一个方法可能会被调用N次,每次调用的上下文可以不一样,不同上下文中这个方法里变量的值会不同;
一个方法里,一个变量在不同位置的值也会不一样。例如一个变量v,在方法执行到第1行和第10行的值会不同;
一个方法里同一个位置的变量的值在程序执行不同路径时也不一样。例如方法foo第10行要用变量v,第10行之前有一个if-else分支会修改v的值,那么程序途径true branch和false branch到达foo第10行时,v的值又不同。
按照我的理解,xxx-sensitive就是在静态分析时,按照xxx给程序里的对象(模拟动态运行)创建“分身”(或者说按照xxx区分分析对象):按照上下文区分叫做context-sensitive;按照位置区分叫做flow-sensitive;按照路径区分叫做path-sensitive。区分之后再分析可以减少false positive。但是静态不可能完全模拟动态的所有情况,因为一旦有递归和循环,理论上你写下的方法和变量就能产生无穷无尽的“分身”。所以静态分析只能或多或少地通过xxx-sensitive技术减少false positive,而不可能消除。
按照定义:path-sensitive最准,flow-次之,context-最差
按照上下文区分:context-sentitive
在提到context-sensitive 时一般context专指function call context,方法调用上下文。
只关心function之间的数据传递(参数、返回值、side-effect)而忽略了同一函数在不同call side下不同的context,即忽略了call stack。将call site和return当作goto,并添加一些赋值语句。
按照位置区分:flow-sentitive
和前两个相比,flow-sensitive 的概念有些混乱。
flow-sensitive要关注statements之间的先后顺序。
flow-insensitive是把statements当作一个集合来看的,各个statement之间没有顺序,所以control flow statement(if、while一类的)可以直接删除;
从SSA的角度来看,path-insensitive是在处理Phi node的时候丢弃分支的信息,只把各个分支来的所有值给merge。path-sensitive是要保留分支信息。
按照路径区分:path-sentitive
path-sensitive其实就是flow-sensitive的一个特例,可以看作是特例或者说携带更高精度的信息的做法。
if、while静态分析时不知道动态的执行路线(path),所以一般会把它们不同的分支的数据流集merge起来。而path-sensitive则针对不同的路径的数据集不会merge,而是分别进行分析。
举例:
1 | if (a > 0) { |
在这段代码的结尾x 的分析结果是如果a > 0 则为1,a <= 0 则为2。
这样分析的精度就高了很多,但是付出的代价是顺着control flow,path 的『分情况讨论』数量随指数增长。当然也有一些优化策略可以在某些情况下降低这个复杂度(比如property simulation)。
soot实现数据流分析
过程内数据流分析
在sootwiki有说到:
过程内数据分析是在以UnitGraph为主的cfg上操作的。
UnitGraph包含语句作为节点,如果控制可以从源节点代表的语句流向目标节点代表的语句,那么两个节点之间就有一条边。
数据流分析将两个元素与UnitGraph中的每个节点联系起来,通常是两个集合:一个inset和一个outset。这些集合首先初始化,然后沿着语句节点在UnitGraph中传播,直到达到一个固定点fixed-point。
最后,你要做的就是在每个语句前后检查inset与outset。通过分析的设计,你的集合特征应该准确地告诉你所需要的信息。
四步走

- 前向or后向?是否考虑分支情况?
- 问题域?那种语句会影响?
- 如何为每一种IR形式的语句写transfer function?
- 如何说明开始情况下的近似值?
义务,必须要做的事情,关键方法

实现你的分析框架,一定要做的事情:
- 必须继承FlowAnalysis抽象类
- 实现抽象方法 : merge() and copy()
- 实现数据流分析函数 :flowThrough()
- 实现初始化函数:newInitialFlow() and entryInitialFlow()
- 框架的构造函数内必须调用 doAnalysis()
这里面doAnalysis() ,其实soot已经实现了在CFG上运用worklist算法进行程序内数据流分析。
三种数据流分析
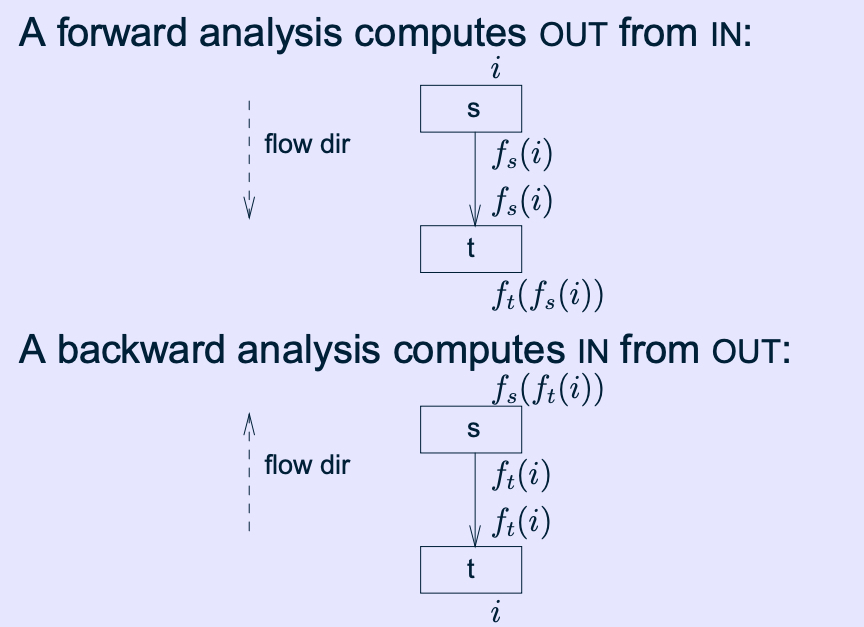
ForwardFlowAnalysis:以UnitGraph的entry statement作为开始并开始传播;
BackwardsFlowAnalysis:以UnitGraph的exit node(s)作为分析并且向后开始传播(当然可以将UnitGraph转换产生inverseGraph,然后再使用ForwardFlowAnalysis进行分析);
ForwardBranchedFlowAnalysis:本质上也是Forward分析,但是它允许你在不同分支处传递不同的flow sets。例如:如果传播到如if(p!=null)语句处,当“p is not null”时,传播进入“then”分支,当“p is null”时传播进入“else”分支(Forward、backward分析都在分支处会将分析结果merge合并掉)。
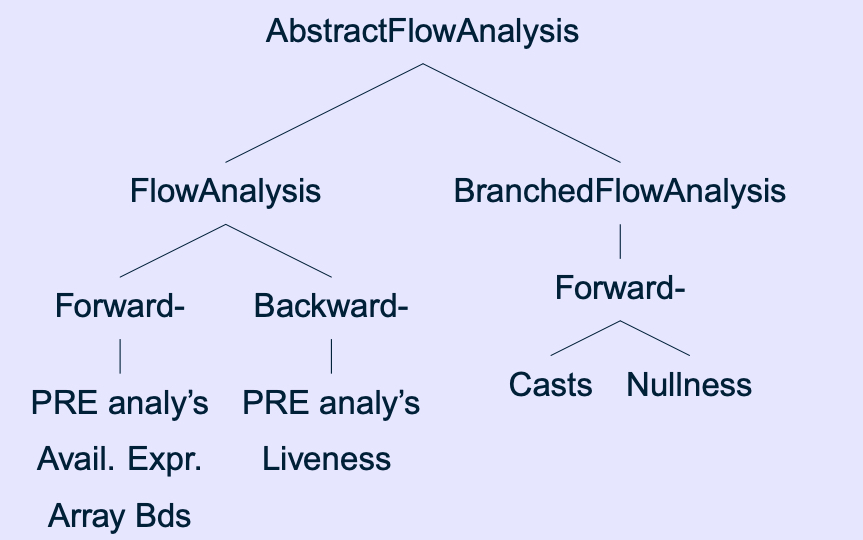
在soot中,FlowAnalysis是一个抽象类。
ForwardFlowAnalysis
ForwardFlowAnalysis是抽象类,继承关系如下:
1 | AbstractFlowAnalysis<N,A> -> FlowAnalysis<N,A> -> ForwardFlowAnalysis<N,A> |
ForwardFlowAnalysis有两个参数:
N:节点种类。通常是Unit。
A:Abstraction Type 抽象类型。人们通常会用Set和Map来表示,但是,Soot要求抽象类型必须正确实现equals()和hashCode()方法,这样Soot才能确定何时到达一个固定点。
关键方法举例

构造函数
必须实现一个携带DirectedGraph作为参数的构造函数,并且将该参数传递给super constructor。然后,在构造函数结束时调用doAnalysis(),doAnalysis()将真正执行数据流分析。而在调用super constructor和doAnalysis之间,可以自定义数据分析结构。
1 | public MyAnalysis(DirectedGraph graph) { //构造函数 |
数据流集合的初始化问题
newInitialFlow & entryInitialFlow
newInitialFlow()方法返回一个抽象类型A的对象,这个对象被赋值给每个语句的in-set和out-set集合,除过UnitGraph的第一个句子的in-set集合(如果你实现的是backwards分析,则是除去exit statement语句)。第一个句子的in-set集合由entryInitialFlow()初始化。
1 |
|
流集合操作
集合复制 copy()
copy()方法接收两个A类型的参数,分别是source和target,该方法其实就是把source复制到target集合里面。
1 |
|
交汇运算 merge()
merge(..)方法被用来在control-flow的合并点处合并数据流集,例如:在句子(if/then/else)分支的结束点。与copy(..)不同的是,它携带了三个参数,一个参数是来自左边分支的out-set,一个参数是来自右边分支的out-set,另外一个参数是两个参数merge后的集合,这个集合将是合并点的下一个句子的in-set集合。
注:merge(..)本质上指的是控制流的交汇运算,一般根据待分析的具体问题来决定采用并集还是交集。
1 |
|
flowThrough(..) 大名鼎鼎的transfer function
flowThrough(..)方法是真正的执行流函数,它有三个参数:A in-set、被处理的N类型节点(一般指的就是句子Unit)、A out-set。这个方法的实现内容完全取决于你的分析。
注:flowThrough()本质上就是一个传递函数。在一个语句之前和之后的数据流值受该语句的语义的约束。比如,假设我们的数据流分析涉及确定各个程序点上各变量的常量值。如果变量a在执行语句b=a之前的值为v,那么在该语句之后a和b的值都是v。一个赋值语句之前和之后的数据流值的关系被称为传递函数。针对前向分析和后向分析,传递函数有两种风格。
1 |
|
Flow-sets
在soot中,flow sets代表control-flow-graph中与节点相关的数据集合。
CFG中的每个节点,都有一个flowset与之关联。
Flow set存在有边界的(需要实现BoundedFlowSet接口)和无边界的(需要实现FlowSet接口)两种表达。
有边界的集合知道possible值的全体集合(适合指针分析),而无边界的集合则不知道。
interface FlowSet<T>
方法:
1 | FlowSet<T> clone(); //克隆当前FlowSet的集合 |
上述方法足以使flow sets成为一个有效的lattice元素。
而对于有边界的flowset,需要实现BoundedFlowSet接口
它需要提供方法,该方法能够产生set‘s complement(补集)和它的topped set(全集)(一个lattice element包括所有的可能的值的集合)。

四种flow sets的实现
ArraySparseSet,ArrayPackedSet,ToppedSet和DavaFlowSet。

ArraySparseSet:是一个无界限的flowset。该set代表一个数组引用。注意:当比较元素是否相等时,一般使用继承自Object对象的equals。但是在soot中的元素都是代表一些代码结构,不能覆写equals方法。而是实现了interface soot.EquivTo。因此,如果你需要一个包含类似binary operation expressions的集合,你需要使用equivTo方法实现自定义的比较方法去比较是否相等。
ArrayPackedSet : 有界flow set。需要提供FlowUniverse 对象,即代表全集的容器。由一个在integer和object双向map和一个用来表示全集成员是否在内的bit vector表示。
ToppedSet : 在基于上面两种的set前提下,加入额外信息来表示其为lattice中的Top。
soot官方例子
Live Variables Analysis
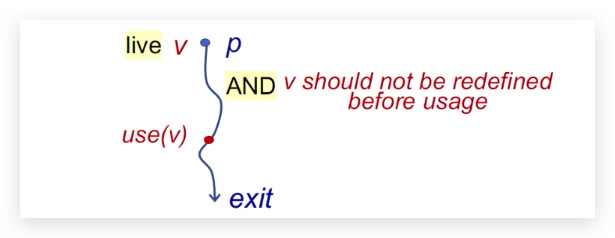
变量v是live状态的条件是:
从v的定义点p开始,v就是活跃的,一直到use(v)地方,中间没有对v的重定义;
step1
May-analysis : BackwardAnalysis 下面这张图 倒着看 效果会更好!
在soot里面,后向分析可以继承BackwardFlowAnalysis抽象类。
汇聚点的操作是union
变量集合可以是继承了FlowSet的ArraySparseSet集合
step2
copy和merge的具体操作:
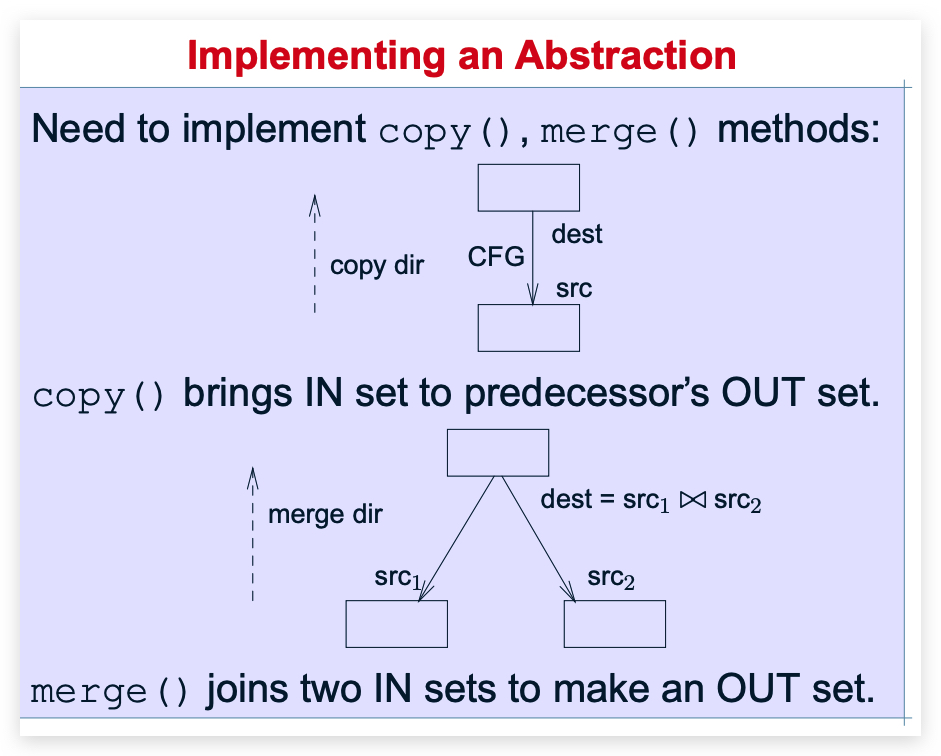
copy()
copy就是直接把当前节点的IN copy 给上一个BB块的OUT

merge()
由于是union , 所以是把分叉点的两个IN union取并集 为分支点的OUT

step3
flowThrough()
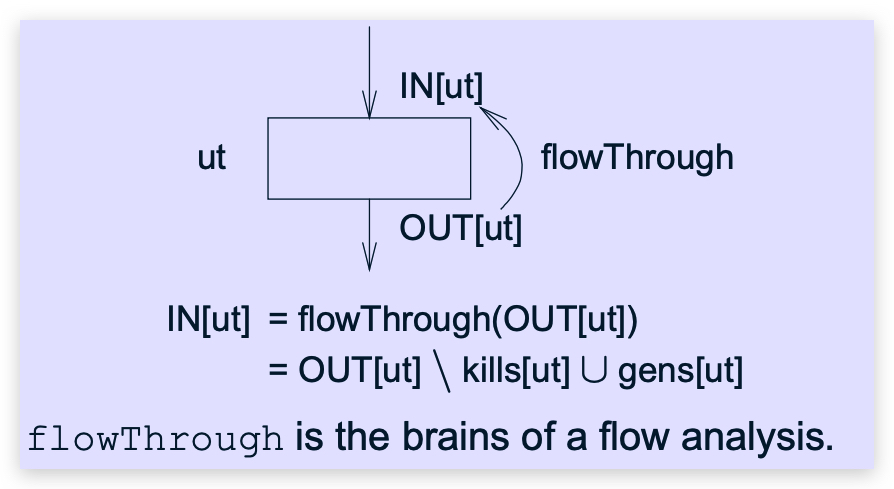
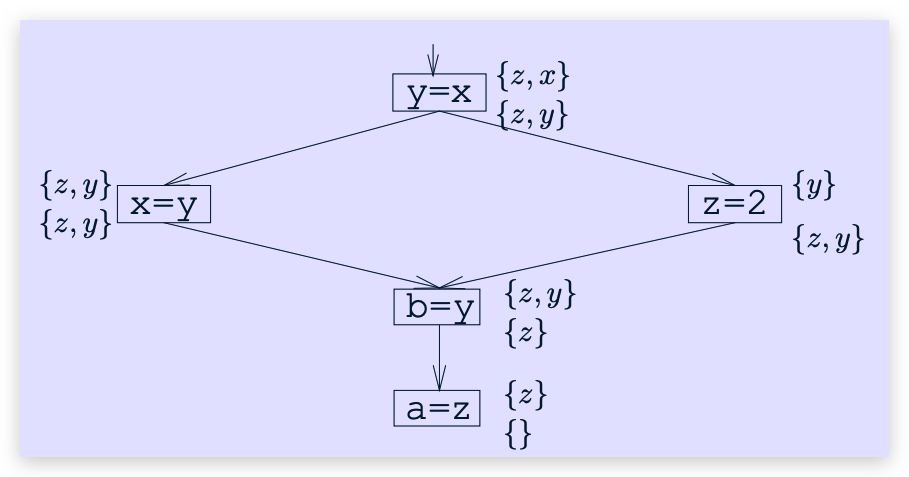
例如: x = y * z
backwardanalysis分析:先kill def[x] ,再 gen use[y,z]
1 | // kill |
step4
Initial values

step5
Constructor

step6
Enjoy result
1 | LiveVariablesAnalysis lv = new LiveVariablesAnalysis(g); |
Branched Nullness Analysis
定义:
如果所有到达s的control-flow path 都导致v被分配了一个非null的值,那么局部变量v在s处就是非null的。
图示:
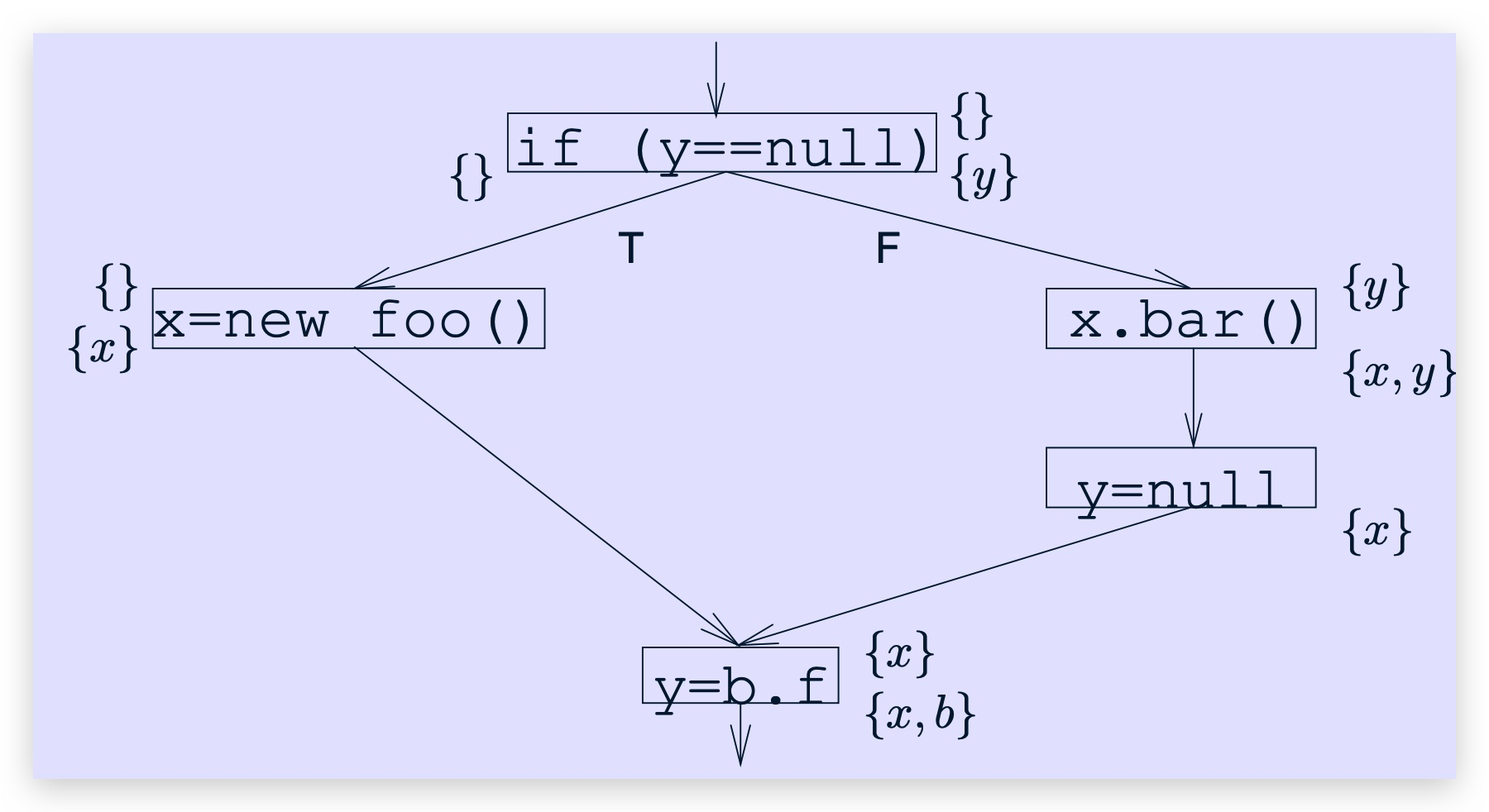
step1
选择实现ForwardBranchedFlowAnalysis
step2
和上一个例子一样:
copy()
forward 正常copy就行
1 | protected void copy(Object src, Object dest) { |
merge()
如果一个变量v在从开始到s的所有路径上都是非空的,那么它就是非空的,所以取交集,intersection()
1 | void merge(...) { |
step3
设计 flow function

零散知识点
以$开头的都是临时变量,表示相对堆栈位置,并不是源程序中的局部变量。
没有$的局部变量则代表真正的局部变量。
jtp是允许用户自定义的,wjtp全程序转换包
clinit方法clinit是类构造器方法,也就是在jvm在进行类加载-验证-解析-初始化中的初始化阶段,jvm会调用clinit. clinit方法是在类加载过程中执行的,而init方法是在对象实例化执行的。
虚方法没有methodbody
soot的控制流图在soot.toolkits.graph这个包内;
Annotating Code
四个接口:
- Host:是可以容纳和管理标签的对象。就像SootClass、SootField、Body、Unit、Value、ValueBox等
- Tag:可以给Host打标记的对象,很通用,用来标记name-vlaue对给Host
- Attribute:是Tag的拓展。任何属于属性的东西都可以输出到文件中。Soot里有一个tool叫做SootClass,可以输出直接码ByteCode,任何应该输出到类文件的东西都必须extend JasminAttribute。
CallGraph的方法调用
Soot中调用图的所有已知方法调用edge边的集合。
包括:
显式方法调用
隐式静态初始化器
隐式调用Thread.run()
隐式调用
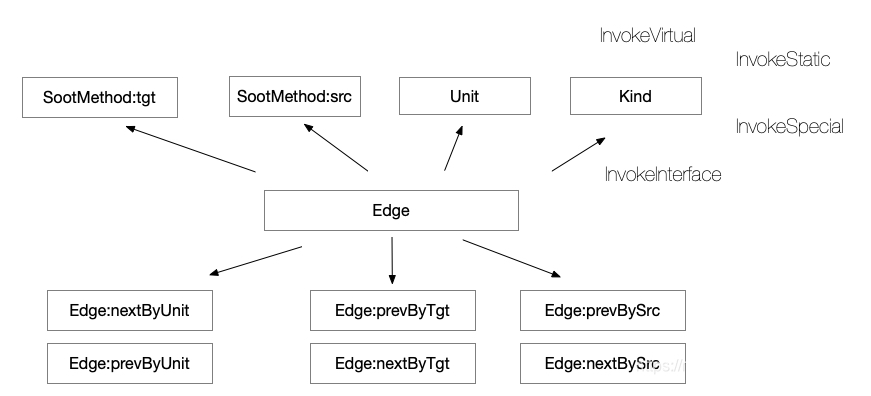
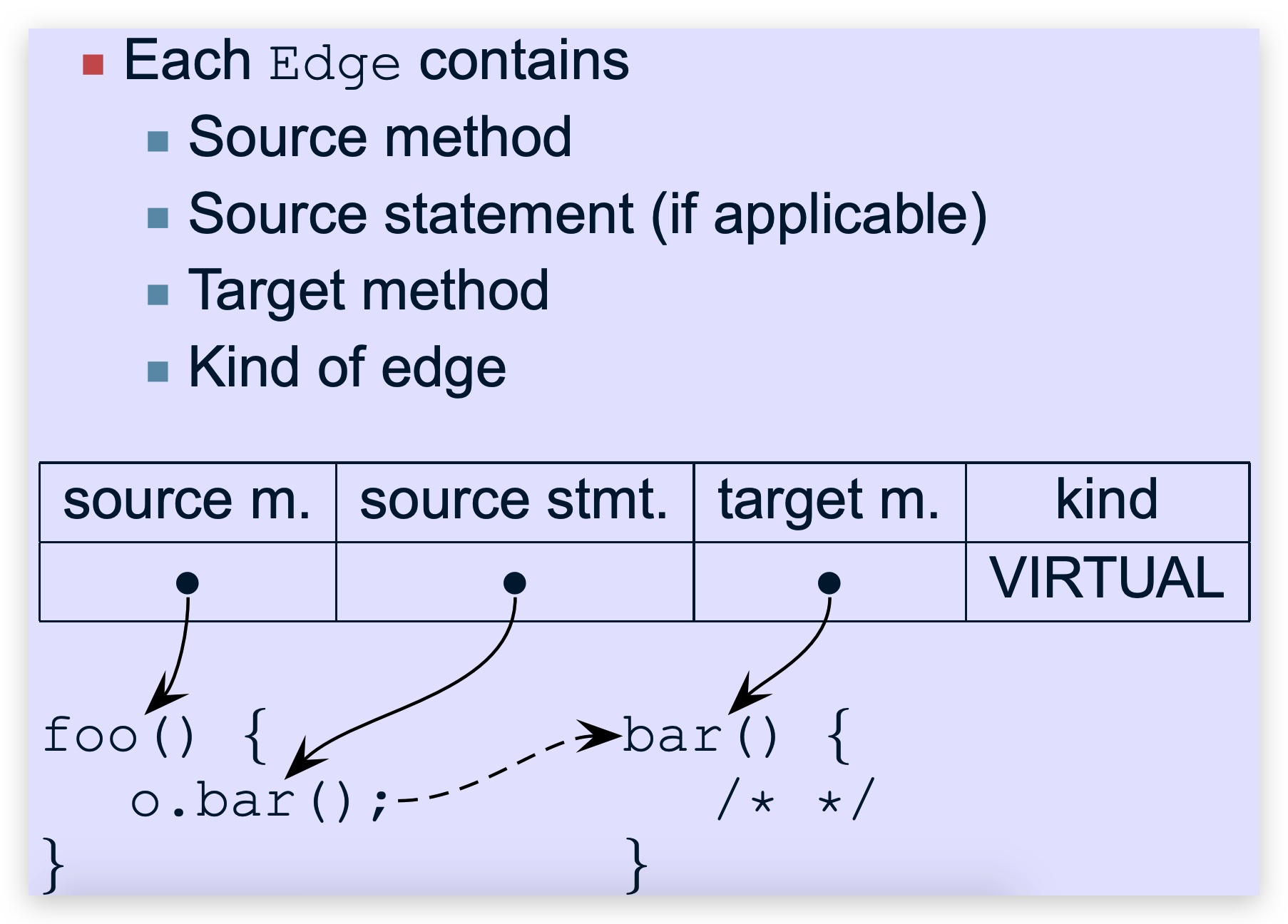
调用图的每一条边edge对象都存在四个元素:
源方法 source method
源语句 source statement
目标方法 target method、
边的种类,例如静态调用invoke static 、虚拟调用 invoke virtual、接口调用invoke interface
CallGraph也有几个经典方法:
edgesInto(method):查询进入method方法的边
edgesOutOf(method):从method方法流出来的边
edgesOutOf(statement):从特定语句statement流出来的边
每个方法其实都会返回一个Iterator来调度Edge边对象
Soot提供了三个适配器来针对Edges进行分析:
- Sources:每条边的原方法
- Units:每条边的原语句
- Targets:每条边的目标方法
例子:
1 | public void printPossibleCallers(SootMethod target){ |
更详细的两个图类:
ReachableMethods and TransitiveTargets
ReachableMethods
表示能从entrypoints开始,能reach到的方法集合
方法contains(method)表示去测试method方法能不能到达,能不能reachable
方法listener()返回的是一个迭代器遍历所有可达方法。
TransitiveTargets
表示从一个特定的方法能指向的所有方法,这个方法可以用来分析调用链。
构造函数接收(除了调用图之外)一个额外过滤器Filter
Filter表示调用图中满足给定的EdgePredicate的边的子集。
EdgePredicate是一组接口,它主要有两个实现,ExplicitEdgespred ,InstanceInvokeEdgesPred;
三个翻译器类:
JavaTranslator、StmtTranslator、ExprTranslator
JavaTranslator负责将给定的Java程序的方法进行翻译,然后将这些翻译之后的语句组合在一起。
它会维护着一个数组,数组会在makeMethod方法之后被初始化。
translate方法是主要方法,这个方法会完成语句的翻译和链接。
StmtTranslator继承了AbstractStmtSwitch,他会翻译单独、独立的语句。
它的主要方法是translateStmt,这个方法其实会把StmtTranslator应用于语句,然后建立一个Map映射对,把Java语句和Jimple代码进行映射,对错误报告很方便。
此外还有一个方法是addStatement,它会将给定的语句添加到指定的方法中,它是整个翻译过程中用来添加语句的方法。
Subexpression是用ExprTranslator(它是AbstractJimpleValueSwitch类的拓展)来翻译的。
切入点是translateExpr方法,他是将Exprtranslator应用到给定的ValueBox上面。
两个有趣方法:
caseSpecialInvokerExpr和handleCall;
caseSpecialInvokerExpr是用来测试是否进行了对象的初始化,如果是的话,那么就创建一个Foo初始化语句;如果不是的话,那么就调用handleCall方法。
过程内分析
数据流分析是针对某一个方法的控制流图(在Soot里面用的是UnitGragh)来分析的。由于是方法内的数据流分析,所以每一个节点都是Stmt语句。
一个UnitGraph会把每条语句作为节点node,两个节点所对应的语句如果能够流通,那么在图上就会有一条边。
每个节点会有两个集合,一个代表入集:in-set,一个代表出集:out-set。
这些集合会随着程序运行实时保存记录,直到遇到一个fixed-point点结束。
在Soot里面有三种数据流分析,分别是Forward/Backward/和Branched
ForwardFlowAnalysis:就是正向的数据分析,从程序的入口点entry point顺着一路下来分析;
BackWardsFlowAnalysis:逆向分析,从程序的结束点exit-node倒推。这里官方文档说可以顺着ForeardAnalysis来继续用,但是需要换成用InverseGraph,以后有空补上这个细节。
ForwardBranchedAnalysis:也是正向分析的一种,只不过会对if这样的分支语句进行分支分析。例如if(p!=null),那么在当分析这一条语句时候,他其实就会自动分出分支,将p is not null放到then分支,然后把p is null放到else分支。
实现Analysis接口
ForwardFlowAnalysis是抽象类,继承关系如下:
1 | AbstractFlowAnalysis<N,A> ->FlowAnalysis<N,A>->ForwardFlowAnalysis<N,A> |
ForwardFlowAnalysis有两个参数:
N:节点种类。通常是Unit
A:Abstraction Type 抽象类型。人们通常会用Set和Map来表示,但是,Soot要求抽象类型必须正确实现equals()和hashCode()方法,这样Soot才能确定何时到达一个固定点。
构造函数:
要求:必须实现一个构造函数,该构造函数至少接收一个DirectedGraph作为参数,其中N为节点类型,并且将它传递给父类的constructor;super.init
并且在自定义的constructor最后,需要调用doAnalysis()函数,这个函数在最后才会分析数据流。
在调用superconstructor和doAnalysis()函数之间,你可以自定义分析数据结构。
方法:
newInitialFlow() and entryInitialFlow()
newInitialFlow()会返回一个抽象类型对象A,这个对象是每个node节点默认初始化的in-set和out-set。
特殊的是entry-point的in-set是通过entryInitialFlow()方法完成的。
copy()方法接收两个A类型的参数,分别是source和target,该方法其实就是把source复制到target集合里面。
The
copy(..)method takes two arguments of type A (your abstraction), a source and a target. It merely copies the source into the target. Note that the class A has to provide appropriate methods. In particular, A may not be immutable. You can work around this limitation by using a box or set type for A.
merge()方法用来在分支汇聚点处汇聚flowsets
它会接收3个参数,分别是左分支和右分支还有一个额外分支,这个额外分支其实是为了下一个节点汇聚而成的in-set。
Opposed to
copy(..)it takes three arguments, an out-set from the left-hand branch, an out-set from the right-hand branch and another set, which is going to be the newly merged in-set for the next statement after the merge point.
最后需要实现的方法是flowThrough();
flowThrough()方法会接收3个参数作为输入:
- A的in-set。
- N类型的node,也就需要待处理的语句。
- A的out-set。
这个方法的内容完全取决于你的分析和抽象。
soot tricks
print in console
1 | soot.SootClass c = // your SootClass |
print to a jimple file
1 | soot.SootClass c = // your SootClass |